
Déclarer la guerre aux données déséquilibrées : SMOTE

Introduction
Les ensembles de données (dataset) déséquilibrés sont courants dans les applications du monde réel, qui vont de la détection de fraude au diagnostic des maladies rares.
Plusieurs algorithmes de classification populaires supposent que les classes sont équilibrées et, par conséquent, construisent la fonction d’erreur correspondante pour maximiser un taux de précision global. Dans le cas d’un dataset non représentatif, le résultat conduirait à des prédictions faussées vers la classe minoritaire (surapprentissage).
De nombreuses méthodes ont été proposées pour résoudre le problème du déséquilibre des classes, y compris des méthodes telles que le suréchantillonnage, le sous-échantillonnage, les méthodes de pondération des coûts, de transfert learning, ou de transformations aléatoires pour les images.
Dans cet article, nous examinerons la méthode de suréchantillonnage, qui vise à compléter le dataset original par des observations synthétiques des classes minoritaires. Nous étudierons plus particulièrement les récents progrès des techniques de modélisation générative comme l’inférence variationnelle (Variational Auto-encoders), comparés avec la technique classique SMOTE.
Dataset
Pour illustration, nous utiliserons un ensemble de données d’images pour détecter les fissures sur les murs.
Nous avons initialement 40K images réparties d’une façon homogène entre les données des murs avec et sans fissure. Afin d’avoir un ensemble de données déséquilibré, nous avons d’abord réduit la taille des données d’entraînement à 10K pour les exemples négatifs (murs sans fissure) et environ 200 images seulement pour les exemples positifs (murs avec fissures).
 Exemple de fissures
|
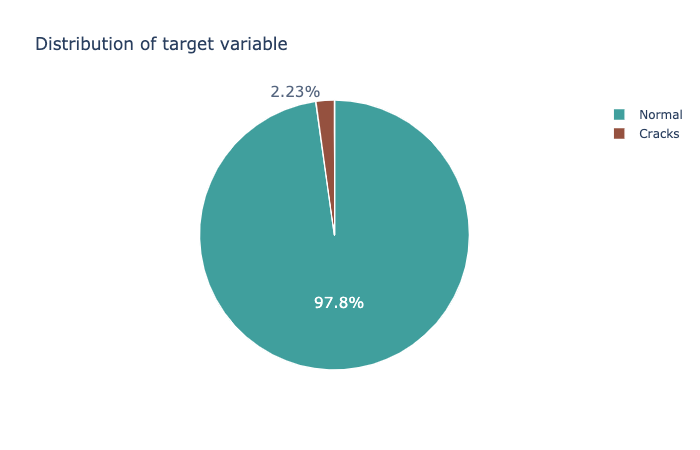 Distribution des deux classes |
Méthodes classiques
Nous ne parlerons pas de toutes les méthodes qui gèrent le manque de données telles que les transformations d’images aléatoires (rotation, translation, recadrage, etc.), ou l’apprentissage par transfert, ni d’autres astuces mathématiques telles que la pondération des classes. Malgré cela, nous vous recommandons vivement d’en apprendre plus sur ces méthodologies qui donnent de bons résultats.
En même temps, d’autres techniques sont couramment utilisées pour gérer ce type problèmes, telles que :
-
Méthodes de sous-échantillonnage : élimination aléatoire de quelques exemples de la classe majoritaire pour diminuer leur effet sur le modèle. En revanche, tous les exemples de la classe minoritaire sont conservés, par exemple Random Undersampling, Edited Nearest Neighbours ou Tomek Links. Cependant, le sous-échantillonnage de la classe majoritaire peut finir par exclure des cas importants qui fournissent des informations nécessaires à la différenciation des deux classes.
-
Méthodes de suréchantillonnage : génération de données supplémentaires (copies, données synthétiques) de la classe minoritaire pour augmenter leur effet sur le modèle. En revanche, tous les cas de la classe majoritaire sont conservés, par exemple Random Over-Sampling, SMOTE ou ADASYN. Cependant suréchantillonner la classe minoritaire peut conduire au surapprentissage du modèle, puisque cela introduira des instances dupliquées d’un ensemble qui est déjà petit.
-
Méthodes hybrides : combinaison des deux stratégies : le sous-échantillonnage et le suréchantillonnage. Par exemple SMOTEENN ou SMOTETomek.
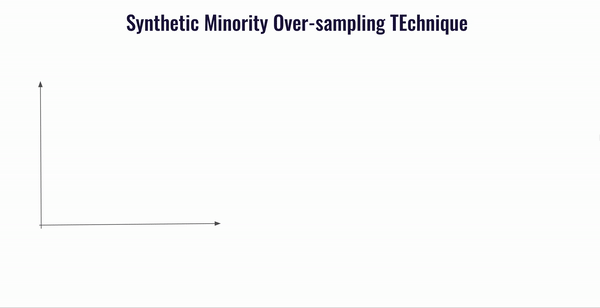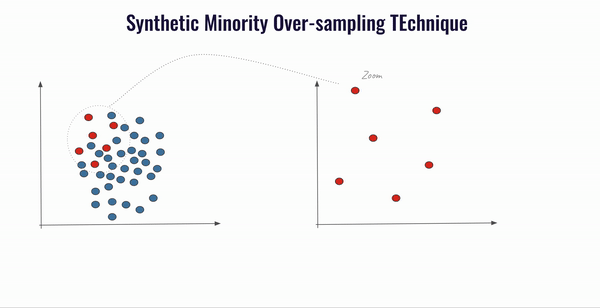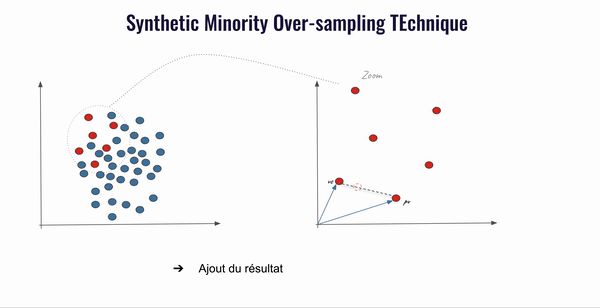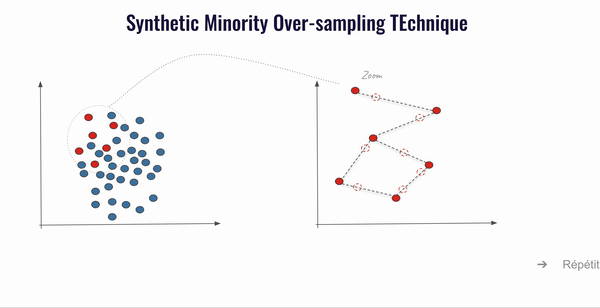
SMOTE
SMOTE (Synthetic Minority Over-Sampling TEchnique) est une technique utilisée pour traiter des ensembles de données déséquilibrées. Introduite pour la première fois par Nitesh V. Chawla, SMOTE est une technique basée sur les plus proches voisins avec une distance Euclidienne entre les points de données dans l’espace des caractéristiques.
De nombreuses modifications et extensions ont été apportées à la méthode SMOTE depuis sa proposition en 2002, telles que : SMOTEN, SMOTENC, SVMSMOTE, KmeanSMOTE, BorderlineSMOTE, ADASYN, etc., permettant de gérer les variables nominales (catégoriques) ainsi que les points dans la frontière.
Comment ça marche :
Le principe de SMOTE est de générer de nouveaux échantillons en combinant les données de la classe minoritaire avec celles de leurs voisins proches. Techniquement, on peut décomposer SMOTE en 5 étapes :
- Choix d’un vecteur caractéristique de notre classe minoritaire que nous appellerons vc ;
- Sélection des k-voisins les plus proches (k=5 par défaut) et choix de l’un d’eux au hasard que l’on appellera pv ;
- Calcul de la différence pour chaque valeur caractéristique (feature value) i, vc[i]-pv[i] et multiplication de celle-ci par un nombre aléatoire entre [0,1];
- Ajout du résultat précédent à la valeur de la caractéristique i du vecteur vc afin d’obtenir un nouveau point (une nouvelle donnée) dans l’espace des caractéristiques ;
- Répétition de ces opérations pour chaque point de données de la classe minoritaire ;

Voici une implémentation les plus utilisées de SMOTE :imbalanced-learn.
from imblearn.over_sampling import SMOTE
seed = 5
smote = SMOTE(sampling_strategy='auto', random_state=seed,k_neighbors=7)
x_train_smote, y_train_smote = smote.fit_sample(x_train, y_train)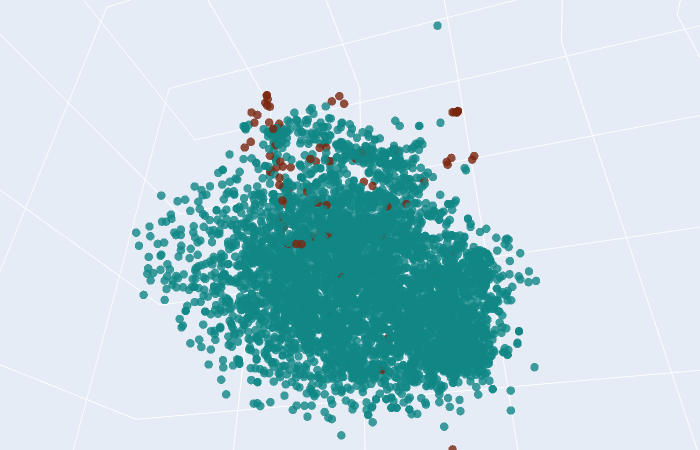 Les données avant suréchantillonnage |
 Les données après suréchantillonnage avec SMOTE |
Conséquences pratiques
SMOTE ne prend pas en compte les exemples voisins qui peuvent provenir d’autres classes. Cela augmenterait la probabilité de chevauchement des classes et introduirait du bruit supplémentaire. L’utilisation d’une des variantes de SMOTE telles que SVMSMOTE, BorderlineSMOTE ou ADASYN permettent de trouver des exemples susceptibles d’être dangereux.
Ainsi, SMOTE montre des difficultés avec les données à grande dimension. C’est pour cette raison que l’utilisation d’une technique de réduction de la dimensionnalité comme l’ACP (Analyse en Composantes Principales) ou l’AE (Auto-Encodeur) avant d’appliquer SMOTE aux données pourrait conduire à de meilleurs résultats.

Conclusion
Pour résumer, SMOTE génère synthétiquement de nouvelles instances de la classe minoritaire en utilisant les instances existantes. Les nouvelles instances créées ne sont pas seulement une copie de ce qui existe, les images générées contiennent de nouvelles formes de fissures, composées de deux formes différentes.
Restez connectés : dans une seconde partie, vous découvrirez comment utiliser les Variationnels auto-encodeurs (VAE) comme méthode de suréchantillonnage.
Références :
SMOTE : www.arxiv.org/pdf/1106.1813.pdf
imbalanced-learn API : www.imbalanced-learn-readthedocs.io/en/stable/api.html
Git : www.github.com/SoatGroup/data_augmentation/blob/master/notebooks/01-smoting.ipynb