
Le NLP au cœur de la data science !

Introduction
L’objectif de cet article est de comprendre à quoi sert le traitement du langage naturel et comment s’en servir. Commençons par définir ce concept.
Le NLP (Natural Language Processing, traitement automatique du langage naturel en français) est une branche de la data science qui désigne un processus d’analyse, de compréhension et d’extraction d’informations à partir de données texte d’une manière intelligente et efficace.
En utilisant le NLP, on peut effectuer de nombreuses tâches automatisées, et résoudre un large éventail de problèmes.
Le NLP implique l’application d’algorithmes pour identifier et extraire les règles du langage naturel. Ceci afin que les données de langage non structurées soient converties sous une forme que les ordinateurs peuvent comprendre.
Dans quels cas d’usage peut-on utiliser le traitement du langage naturel ?
Le traitement du langage naturel (NLP) permet de répondre à différents besoins, à savoir :
- traduction de texte
- résumé automatique de texte
- classification de texte (ce qui permet de filtrer les spams dans nos boîtes mail par exemple)
- analyse de sentiments/opinions/discours
- assistants vocaux (Google Assistant, Apple Siri, Amazon Alexia…)
- chatbots
- traduction des vidéos
- extraction des entités nommées depuis un texte (ex : nom propre ou lieu)
Pour pouvoir utiliser les algorithmes de Machine et Deep Learning avec le NLP, il nous faut tout d’abord savoir préparer notre corpus avant de connaître quelles sont les méthodes qui permettent de transformer ce dernier en features exploitables par ces programmes.
Les Frameworks les plus utilisés avec Python
Une librairie NLP est une boîte à outils qui traite des données non structurées de différentes sources, ce qui nous permet de les comprendre et d’obtenir des informations précieuses.
Je vous propose de passer en revue les 4 bibliothèques NLP les plus utilisées en Python :
NLTK
Le Natural Language Toolkit est relativement mature (il est en développement depuis 2001) et s’est positionné comme l’une des principales ressources en matière de traitement du langage naturel. NLTK possède des outils pour presque toutes les tâches NLP.
Dans le domaine du traitement du langage naturel le NLTK est un excellent point de départ pour débuter.
Attention, NLTK peut devenir lent lors de la gestion d’applications métier complexes.
Pour plus de details : nltk.org
Gensim
Gensim est une bibliothèque hautement optimisée pour la modélisation sémantique non supervisée (Topic modeling : LDA, LSI…) et la similitude de documents.
Gensim regroupe les mêmes types d’outils que NLTK : tokenisation, POS-tagging, NER, analyse de sentiments, lemmatisation…
Gensim permet de faire du Word Embedding et de télécharger des modèles pré-entraînés (Glove, fastText, Word2vec…). En outre, un autre avantage significatif de gensim est qu’il vous permet de gérer de gros fichiers texte sans avoir à charger le fichier entier en mémoire.
Pour plus de details : radimrehurek.com/gensim
spaCy
SpaCy est une librairie plus récente (2015) qui fournit la plupart des fonctionnalités standard (tokenisation, analyse, reconnaissance d’entités nommées…).
Elle est conçue pour être très rapide.
SpaCy est une évolution de NLTK et offre aux utilisateurs une expérience beaucoup plus fluide, plus rapide et plus efficace.
SpaCy est plus utilisé dans l’extraction et l’analyse de données, la synthèse de texte et l’analyse des sentiments.
Pour plus de details : spacy.io
Pytorch-transformers
Pytorch-transformers est un package de modèles pré-entraîné pour le traitement automatique du langage naturel (NLP).
Parmi ces modèles, nous pouvons citer BERT (modèle de langage développé par Google en 2018 basé, sur des réseaux de neurones et pré-entraîné sur Wikipédia dans plus de 104 langues).
Les transformers sont bons pour :
- prédire si une phrase est la suite d’une autre
- les tâches de questions/réponses
- la traduction automatique
- la génération de texte
La différence entre ces packages réside dans la philosophie générale de l’approche de résolution de problèmes. Le choix du package NLP dépend donc du problème spécifique que nous devons résoudre.
Nous notons aussi l’existence d’autres librairies du NLP en python et dans d’autre langages (Java, R…).
Par exemple : Stanford Core NLP, Apache OpenNLP, cleanNLP, scikit-learn…
Préparation du texte pour le traitement du langage naturel
Avant qu’un texte donné soit utilisable, il doit subir un prétraitement. La première phase effectuée dans le traitement du texte est la transformation des majuscules en minuscules.
L’étape suivante sera la suppression des stopwords, listes de mots définis au préalable soit par l’utilisateur soit dans des librairies existantes (en français : à, le, la, et…) qui n’ont pas de valeur informative pour le sens du texte.
La liste des stopwords dépend de l’objectif final de chaque cas d’usage (suppression des mots les plus fréquents par exemple).
Ensuite, nous faisons notre « tokenisation » (on découpe le corpus en mots) en ignorant les stopwords.

Tokenisation
La « lemmatisation » prend en considération le contexte dans lequel le mot est écrit, et consiste à représenter les mots sous leur forme canonique. L’idée étant toujours de ne garder que le sens des mots utilisés dans le texte (corpus).
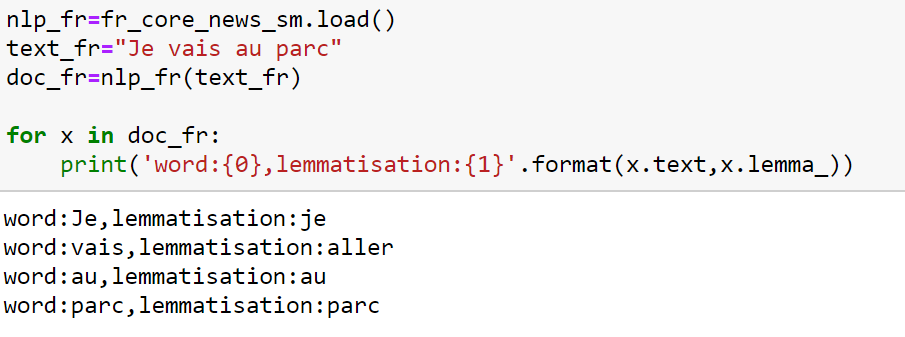
Lemmatisation
La Racinisation est similaire à la lemmatisation mais plus rapide, et consiste à ne conserver que la racine des mots étudiés (suppression des suffixes, préfixes…).
Elle ne prend pas en compte le contexte de la phrase.
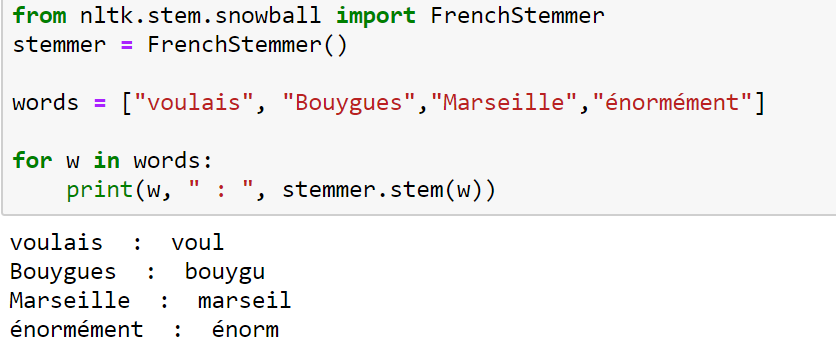
Racinisation
Conclusion
Dans cet article d’initiation au NLP nous avons :
- énuméré différents exemples de cas d’usage d’application du NLP,
- présenté les librairies les plus utilisées avec python,
- tracé les grandes étapes de préparation de corpus : du texte brut jusqu’aux données exploitables.
Nous venons de voir comment préparer un corpus, nous verrons prochainement comment transformer ce corpus nettoyé en données numériques exploitables par les algorithmes classiques de la data science.
Je serais heureux de savoir si vous avez de nouvelles approches ou suggestions à travers vos commentaires.
Bon apprentissage !