
Architecture et programmation réactives avec Akka et Scala – Partie 2

Dans le premier blog post de la série “Architecture et programmation réactives avec Akka et Scala”, on avait premièrement rappelé le contexte global duquel a émané le paradigme de la réactivité, par la suite on a fait un rapide tour d’horizon des bibliothèques réactives ciblant la JVM, et enfin introduit l’architecture commune de base.
Dans cette deuxième partie, on va entamer l’aspect pratique proprement dit. On introduira en premier la structure du projet exemple en Scala, puis on fera la connaissance du système d’acteur et voir ce qu’il représente pour Akka Streams, enfin on verra d’intéressantes notions d’architectures dans Akka Streams à savoir la modularité et la composition.
Réactivité en pratique avec Akka Streams et Scala
Il faut d’une part savoir que Scala est un langage qui fait partie de la famille JVM. C’est-à-dire que son compilateur cible la JVM en générant du “bytecode” Java à exécuter par cette dernière. Cela lui confère la capacité d’intégrer nativement toutes les bibliothèques écrites en Java: On parle alors d’interopérabilité de Scala avec Java.
D’autre part Akka est l’une des bibliothèques phare du monde Scala, bien qu’elle existe tout aussi pour Java. Et comme évoqué dans le premier blog post, se basant sur le modèle du système d’acteur d’exécution concurrentielle (voir ci-bas “Le système d’acteur dans Akka”), Akka évite de reproduire les problématiques liées au modèle de multi-threading bloquant de Java.
Offrant une gamme de plusieurs sous-modules comme Akka Actors, Akka HTTP ou encore le module sophistiqué Akka Cluster, on utilisera uniquement lors des manipulations qui suivront Akka Streams; ce module étant une implémentation des paradigmes de la réactivités tels qu’énoncés dans “The reactive manifesto”
Dans les exemples qui suivront, on utilisera un mode de présentation “macro” où sera introduite une vue globale du projet avec son socle principal et sa structure Sbt (outil de gestion des projets Scala, équivalent de Maven ou Gradle pour les projets Java).
Par la suite, au fur et à mesure de l’avancement, des explications sous la forme de notes informatives accompagneront, quand nécessaire, les points à éclaircir.
Place à présent au vif du sujet ! Voici le plan qu’on suivra :
- Structure et définition du projet
- Le système d’acteur dans
Akka - Projet exemple
- L’instance d’exécution
- Architecture basique de
Akka Streams - Modularité et composition
Structure et définition du projet
Pour des raisons d’homogénéité, Sbt (Simple Build Tool) adopte une structure presque identique à celle d’un projet standard Java bien qu’il soit possible de faire autrement.
Dans notre exemple, on aura alors comme structure du projet :
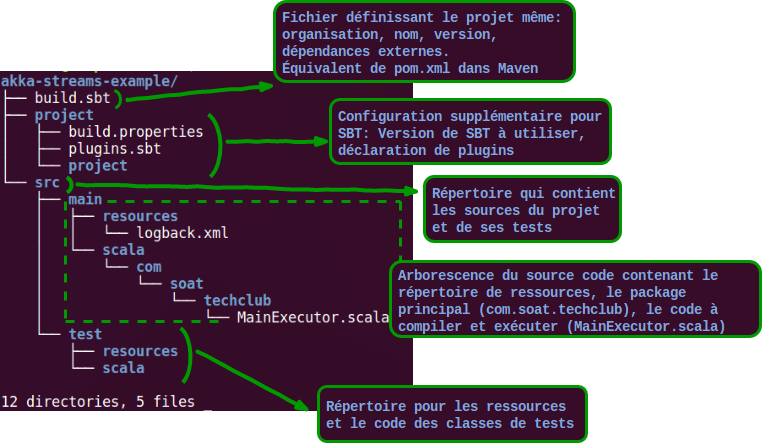
On va maintenant modifier le contenu du fichier <span style="text-decoration: underline">build.sbt</span> pour déclarer les propriétés du projet ainsi que ses dépendances externes. Rajoutons les lignes suivantes :
organization:="com.soat.techclub"
name:="akka-streams"
version:="1.0"
scalaVersion:="2.12.8"
libraryDependencies++=Seq(
"com.typesafe.akka" %% "akka-stream" % "2.5.22",
"com.typesafe.scala-logging" %% "scala-logging" % "3.9.2",
"ch.qos.logback" % "logback-classic" % "1.2.3")
scalacOptions++=Seq("-feature","-language:postfixOps")
- Lignes 1,2,3définition de l’identité ou des coordonnées uniques du projet. Organisation à laquelle il appartient, son nom et sa version (même système d’identification que
Maven)
- Ligne 4
la version deScalaà utiliser dans ce projet
- Lignes 6,7,8,9
déclaration des dépendances (bibliothèques) externes qui prend la forme d’une séquence ou liste :akka-stream,scala-loggingetlogback-classicpour le logging
- Ligne 11
quelques options pour le compilateurscalac
- Notes générales sur
Sbt- La définition d’un projet
Sbtse base sur un ensemble de clé/valeur où chaque clé est d’un typeScaladonné. - Par exemple, la clé
scalaVersionest de typeSettingKey[String](une clé-propriétéSettingKeyencapsulant une valeurString) à laquelle on affecte une valeur via l’opérateur:=. - Un peu plus particulière, la clé
libraryDependenciesest de typeSettingKey[Seq[ModuleID]]. Pour simplifier, disons que c’est une clé-propriété encapsulant une séquenceSeq(ou liste pour certains) : on retiendra alors son type commeSettingKey[Seq[_]].
On remarquera cette fois que l’opérateur d’affectation devient++=. Cela est dû au fait qu’on concatène une nouvelleSeqà la clélibraryDependenciesdont le type estSeq. - La déclaration d’une classe générique
Genavec le paramètre typeTse fait (dansScalaen général) :class Gen[T] {...} - Les dépendances sont déclarées sous la forme
groupId <strong>%%</strong> artifactId <strong>%</strong> versionétant donné qu’elles sont retrouvées par défaut depuis lerepositorycentral deMaven.
À noter une légère différence entre les opérateurs%%et%. Le premier concatène tout simplement la version deScaladu projet au nom de l’artifactId, ce qui nous donne concrètement pour notre exemple :
–"com.typesafe.akka" <strong>%%</strong> "akka-stream" <strong>%</strong> " 2.5.22"
est équivalent à
–"com.typesafe.akka" <strong>%</strong> "akka-stream<strong>_2.12</strong>" <strong>%</strong> "2.5.22"
- La définition d’un projet
Le système d’acteur dans Akka
Akka a fait le choix de ne pas s’appuyer sur le modèle d’exécution concurrente bloquant natif à Java, puisque ce dernier fait que les thread s en cours d’exécution se suspendent mutuellement.
À petite échelle, le blocage pourrait ne pas entraver de façon significative l’exécution d’une application, mais à partir d’une certaine dimension la synchronisation risque de devenir trop complexe.
De la sorte, une partie non négligeable des efforts de conception et développement d’un projet seraient focalisés sur les problématiques d’interblocage (deadlock), famine (starvation) et autres. Surtout avec les outils natifs à Java comme les blocs synchronized {…}, les lock ou les semaphore qui ne garantissent pas un comportement déterministe.
Entre en jeu alors un modèle avec une approche différente, non bloquante, dite exécution asynchrone : il s’agit du modèle d’acteur.
Historiquement apparu au courant des années 1970s, le principe de base stipule qu’un groupe d’entité nommée acteur interagit ensemble dans le but d’assurer une exécution concurrente non bloquante, donc plus fluide et plus performante.
L’article suivant sur le blog de SOAT traite le sujet des acteurs avec plus de détails : Les systèmes réactifs et le pattern actor model
Le modèle d’acteur a un impact direct sur la conception à l’architecture qui devient désormais nettement plus facile à élaborer. En effet, la disparition de la synchronisation et de tous ses aspects négatifs a pour effet de dé-complexifier la réflexion autour de la construction des applications.
Pour résumer, si on avait à présenter le modèle acteur en quelques points, on dirait :
- un acteur est caractérisé par un état propre confiné et un comportement bien défini (analogue à la définition de l’objet dans le paradigme orienté objet)
- un acteur interagit avec d’autres acteurs à travers l’envoi de messages sans l’attente d’une réponse immédiate (d’où l’asynchronisme et le non-blocage)
- l’ensemble des acteurs coexistent dans un système d’acteur et sont structurés selon une hiérarchie père-fils.
Pour le cas d’Akka, le système d’acteur est son moteur d’exécution et ce pour tous ses modules, y compris donc pour Akka Streams.
Pour plus de détails sur le fonctionnement d’ Akka avec le modèle d’acteur, se référer à cet article de blog de SOAT : Akka.Net – les fondamentaux
Projet exemple
Une fois la structure et la définition du projet établies, on peut passer désormais à l’étape de codage proprement dite.
Instance d’exécution
Découvrons alors le contenu du fichier source MainExecutor localisé sous le package com.soat.techclub.
MainExecutor.scala
package com.soat.techclub
import com.typesafe.scalalogging.Logger
object MainExecutor extends App {
val logger = Logger(MainExecutor.getClass)
logger.info("Ceci est un message de log ;)")
}
- Ligne 5On déclare l’objet
MainExecutoréponyme du fichier source avec le mot cléobjectpour exprimer le fait qu’il s’agisse d’une instance unique. Un peu l’équivalent d’un champ statique dans une classeJava. Cela a du sens puisqu’on utilise une seule instance de cette entité pour lancer l’exécution.
L’objetMainExecutorhérite d’untrait, une sorte d’interface dansScala, nomméApp.
Cela permet d’exécuter les instructions se trouvant directement dans le corps délimité par les accolades{ … }et d’éviter ainsi de déclarer la méthode principale exécutante comme dansJava: la fameusepublic static void main(String[] args){ … }.
- Ligne 7Les messages de log seront affichés grâce à l’objet
loggerqu’on a instancié à l’aide du constructeurLoggerde la dépendancescala-logging. Dépendance rajoutée plus haut dans le fichierbuild.sbt.
Un point à ne pas manquer aussi : on notera l’utilisation du mot clévaluniquement, avec l’absence du type d’objet pour la déclaration dulogger. Si on bénéficie d’une syntaxe légère, c’est que derrière les coulissesScala, malgré les apparences, c’est un langage fortement typé qui se dote d’un compilateur intelligent sachant inférer le type d’une variable déclarée.
- Ligne 8
L’instruction qui affichera le message de log sur la sortie standard de la console.
Pour lancer l’instance exécutive MainExecutor il suffit de se placer à la racine du répertoire du projet, là où se trouve le fichier build.sbt, puis de lancer la commande sbt run. On verra s’afficher sur la console alors :
[info] Done packaging. [info] Running com.soat.techclub.MainExecutor [run-main-0] INFO c.s.t.MainExecutor$ - Ceci est un message de log 😉 [success] Total time: 12 s, completed May 12, 2019 10:38:29 PM
La finalité de MainExectuor est de servir de socle d’exécution pour notre projet-exemple. Ainsi, tout le code et toutes les instructions à lancer seront localisés dans le corps de cet objet.
Architecture basique de Akka Streams
Comme déjà évoqué dans la section Architecture commune du premier blog post, Akka Streams implémente l’architecture de base dont la finalité est de définir le flux où transiteront les objets émis.
Voyons de plus près comment cela se traduit en code, rajoutons les instructions suivantes dans le corps de l’instance d’exécution MainExecutor.scala:
implicit val actrSys = ActorSystem("Soat-ActorSystem")
implicit val actMatrlzer = ActorMaterializer()
val logger = Logger(MainExecutor.getClass)
val origin = 1 to 25
val source: Source[Int,NotUsed] = Source(origin)
val flow: Flow[Int,String,NotUsed] = Flow[Int].map(i => i.toString * 3)
val sink: Sink[String,Future[Done]] = Sink.foreach[String]( str => logger.info(s"Triple i => $str"))
val runnableGraph: RunnableGraph[NotUsed] = source.via(flow).to(sink)
val runGraph: NotUsed = runnableGraph.run
- Lignes 1,2Ici on déclare et instancie le moteur d’exécution, un système d’acteur nommé
"Soat-ActorSystem"référencé paractrSys. Pareillement, on déclare et instancie dans un deuxième temps unActorMaterializerréférencé paractMatrlzer.
Si on a définiActorSystemcomme le moteur d’exécution,ActorMaterializerquant à lui possède un rôle de concrétisation ou de matérialisation. Il est responsable de l’instanciation et du lancement effectif d’un flux.
On notera lors de la déclaration des deux dernières valeurs (val) l’utilisation d’un nouveau mot clé :implicit.
- Lignes 6,7on déclare une suite d’entier
Intde1à25nomméeorigin(clin d’œil à l’élégance syntaxique) qu’on fournira comme argument au constructeurSource. Ce constructeur retournera un objet, analogue auPublisher(vu dans Architecture commune du premier blog post), qui sera la source d’émission du flux.
Le typeSource[Int,NotUsed]déclaré explicitement (sans inférence de type) après source, indique que les objets émis seront de typeInt.
Aussi lors de la matérialisation ou exécution effective, on aura un objet retour de typeNotUsed. Autrement dit, on va tout court ignorer l’objet retourné au moment de la matérialisation.
- Ligne 9De la même manière, on déclare et instancie un objet
flowanalogue àOperator(voir Architecture commune du premier blog post) dont le type explicite estFlow[Int,String,NotUsed].
Cela veut dire que cet étage du flux recevra des objets de typeIntet émettra des objets de typeString. On introduit ainsi une transformation exprimée grâce à la méthodemapprenant une expressionlambdacomme argument.
Ici l’expression lambda transforme chaqueInten sa valeurStringrépétée 3 fois (encore un clin d’œil à l’élégance de la syntaxe).
- Ligne 10Idem, déclaration et instanciation d’un objet
sinkde typeSink[String,Future[Done]](analogue àSubsriberdans Architecture commune du premier blog post) indiquant que les objets reçus seront de typeStringet que lors de la matérialisation il y aura retour d’un objet de typeFuture[Done].
Cet objet retourné n’est pas disponible au moment de l’exécution, il le sera dans le futur. On pourra de la sorte à un moment ultérieur s’assurer que l’exécution du flux s’est terminée.
Ce que lesinkfera avec les objets reçus est décrit encore avec une expressionlambdapassée en argument à la méthodeforeach: Maniant lelogger, on affiche simplement un message avec la valeur duStringreçu en amont.
On notera le formatage de la chaîne de caractère préfixée avecset contenant la valeur de la variable à interpréter$str.
- Ligne 12On connecte les étages source,
flowetsinkpour former un flux linéaire à travers la méthodeviapour raccorder les typesFlowet la méthodetopour raccorder les typesSink.
L’objet de retourrunnableGraphest de typeRunnableGraph[NotUsed], c’est-à-dire graphe (linéaire dans notre cas) à exécuter retournant un objetNotUsedau moment de la matérialisation.
L’objetNotUsedprovient par défaut de l’étage le plus à gauche : c’est-à-dire depuissourcepour cet exemple. Il est bien évidement possible de changer ce comportement afin de retourner celui d’un autre étage :flowousink.
- Ligne 13On exécute le graphe composé précédemment et on obtient l’objet retourné suite à la matérialisation.
Lançons le code précédent avec la commande sbt run et voyons le résultat de l’exécution :
[info] Done packaging. [info] Running com.soat.techclub.MainExecutor [akka.actor.default-dispatcher-2] INFO c.s.t.MainExecutor$ - Tripled => 111 [akka.actor.default-dispatcher-2] INFO c.s.t.MainExecutor$ - Tripled => 222 [akka.actor.default-dispatcher-2] INFO c.s.t.MainExecutor$ - Tripled => 333 [akka.actor.default-dispatcher-2] INFO c.s.t.MainExecutor$ - Tripled => 444 ...
On voit bien comment chaque entier est dupliqué 3 fois puis affiché dans le message de log.
Dans cet exemple, il existe certes des détails d’implémentation spécifiques à Akka Streams comme la terminologie Source, Flow, Sink et la méthode de construction du flux. Ou bien aussi des éléments syntaxiques et sémantiques propres au langage Scala.
Mais en coulisses, c’est toujours la même architecture définie précédemment qui régit le fonctionnement du système réactif.
L’empreinte du modèle d’un flux ressemblant à une chaîne de montage industrielle reste fortement ressentie.
- Notes générales sur
Scala- Les mots clés
valetvarsont utilisés respectivement pour la déclaration des constantes et des variables.
Par exemple, la syntaxe de déclaration d’une variable nomméexyzde typeTest<strong>var</strong> xyz : T = ... - Placé devant une
val/var, une méthode ou une classe, le mot cléimplicitrendra disponible cetteval/var, méthode ou classe discrètement ou encore implicitement dans le contexte ou scope actuel.
Concrètement, prenons le cas d’une méthode qui dans sa signature déclare un paramètre comme étantimplicit. Il faudra lors de l’invocation soit lui passer explicitement un argument soit le déclarerimplicitdans le scope en cours sans le lui passer.
Dans l’exemple précédent, le constructeurActorMaterializer()a besoin d’un objetActorSystemimplicite dans le contexte pour créer son instance. C’est pour cela que la constanteval actrSysa été marquée commeimplicit.
- Les mots clés
Modularité et composition
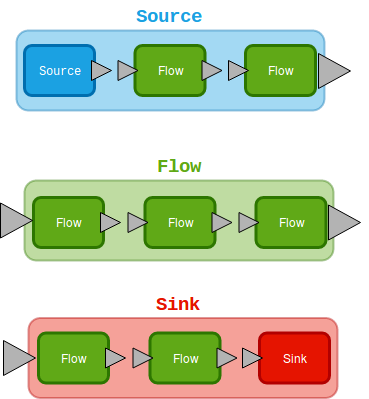
La section précédente a introduit les 3 composants fondamentaux de Akka Streams à savoir Source, Flow et Sink qui lorsque connectés forment le flux ou graphe linéaire de base RunnableGraph. Mais qu’arriverait-il si on connectait ces étages que partiellement ? Que pourrait-on bien avoir ?
Faisons l’expérience avec le snippet suivant :
val source = Source (1 to 10)
val flow = Flow[Int].map( i => i.toString )
val stage = source.via(flow)
logger.info(s"Class is >>> ${stage.getClass}")
On instancie un étage Source qui émet une séquence de Int de 1 à 10, puis un étage Flow qui transforme les Int en String. Par la suite on connecte les deux étages source et flow grâce à la méthode via et on récupère le résultat dans la constante stage.
Affichons la classe de stage avec le formatage de la chaîne de caractère préfixée par s.
- Notes générales sur
Scala- Pour formater une chaîne de caractère dans
Scalail faut la préfixer avecs.
L’interprétation du contenu se fait avec le symbole$pour une valeur simple et avec${ … }pour une expression.
Cela s’appelle String interpolation.
- Pour formater une chaîne de caractère dans
Nous obtenons à la console :
[run-main-2] INFO c.m.l.MainExecutor$ - Class is >>> class akka.stream.scaladsl.Source
La classe obtenue est de type Source.
On conclut donc qu’un objet Source[T,_] raccordé à un objet Flow[T,G,_] donne lieu à un objet de type Source[G,_] (l’emploi du _ signifie qu’on ignore le type de la matérialisation).
Et quand on enchaîne avec le même raisonnement, si on reprend le dernier objet de type Source[G,_] et qu’on le raccorde à un autre objet de type Flow[G,P,_] cela donne lieu à un objet Source[P,_].
La conclusion finale est que de façon globale, si on raccorde Source[T0,_] avec Flow[T0,T1,_] puis Flow[T1,T2,_] jusqu’à Flow[Tn-1,Tn,_] on obtient un objet dont le type est Source[Tn,_].
Traduisons cela en code :
val source = Source (1 to 10) val flow0 = Flow[Int].map( i => i.toFloat ) val flow1 = Flow[Float].map(f => f.toString) val flow2 = Flow[String].map(str => str.length < 4 ) val stage: Source[Boolean,_] = source.via(flow0).via(flow1).via(flow2)
- Ligne 1
une source qui génère desIntde1à10
- Ligne 3
flow0reçoit des objetsIntet retourne desFloat
- Ligne 4
flow1reçoit des objetsFloatet retourne desString
- Ligne 5
flow2reçoit des objetsStringet retourne desBoolean
- Ligne 7
On enchaîne les raccordements avec la méthodeviapour former uneSource[Boolean,_].
À noter que si on change le type paramètre destageà autre chose queBooleanle compilateur marquera le type déclaré en erreur. Cela est dû au fait que le dernier étageflow2émet unBooleandonc la source résultante doit absolument retourner un objetSource[Boolean,_].
En appliquant symétriquement le même raisonnement aux objets de types Flow et Sink on arrivera aux conclusions suivantes :
- Le raccord de
Flow[T0,T1,_]puisFlow[T1,T2,_]jusqu’àFlow[Tn-1,Tn,_]donnera lieu à un objet de typeFlow[T0,Tn,_]. - Le raccord de
Flow[T0,T1,_]puisFlow[T1,T2,_]jusqu’àFlow[Tn-1,Tn,_]avec en dernier unSink[Tn,_]donnera lieu à un objet de typeSink[T0,_].
Construisons un exemple plus illustratif et plus concret qui aidera à mieux assimiler tous ces symboles.
Prenons le bout de code suivant :
def squareSource(intSeq:Seq[Int]) : Source[Int,_] = {
Source[Int](intSeq)
.via( Flow[Int].map(i => i * i) )
}
def formatSink(msg:String) : Sink[Int,_] = {
Flow[Int]
.map(i => msg.format(i))
.via(
Flow[String].map(str => str concat " !!"))
.to(
Sink.foreach[String](str => logger.info(str)))
}
squareSource(3 to 9).to(formatSink("Squared = %s")).run
- Ligne 1
On déclare une fonctionsquareSourcequi prend en paramètre uneSeqde type Int (liste ou séquence d’entier) et qui retourne comme résultat uneSourceémettant desInt.
- Lignes 3,4
À l’intérieur on crée un objetSourceà partir de la liste passée en paramètre qu’on raccorde avecviaà unFlownouvellement créé. Cet objetFlowva émettre la valeur du carré de l’entier reçu comme le décrit l’expressionlambda</codecode class="language-plaintext">i ⇒ i * i.
Cette composition forme l’objet à retourner par la fonction.
- Ligne 7
On déclare une fonctionformatSinkacceptant un paramètre de typeStringet retournant unSinkayant en réception un typeInt. Le paramètre contiendra un message à formater avec les objetsIntreçus.
- Lignes 9,10,11,12,13,14
on instancie et raccorde deux objets de typeFlow. Le premier reçoit desIntdont il utilisera la valeur pour formater le paramètremsget le deuxième concatènera à la chaîne formatée la chaîne!!. Un dernier objetSinkvient se raccorder avectoaux étages précédents pour afficher avec leloggerle résultat obtenu.
La composition de ces 3 étages forme l’objetSink[Int]à retourner par la méthode.
- Ligne 17
En une seule étape, on appelle les fonctions déclarées précédemment qui retourneront les étages construits puis on les raccorde en utilisanttouniquement (on dispose que d’unSourceet unSink) et enfin on exécute le graphe linéaire avecrun.
En lançant notre petit programme toujours avec la commande sbt run on obtient :
[info] Running com.soat.techclub.MainExecutor ... [akka.actor.default-dispatcher-4] INFO c.m.l.MainExecutor$ - Squared = 36 !! [akka.actor.default-dispatcher-4] INFO c.m.l.MainExecutor$ - Squared = 49 !! [akka.actor.default-dispatcher-4] INFO c.m.l.MainExecutor$ - Squared = 64 !! [akka.actor.default-dispatcher-4] INFO c.m.l.MainExecutor$ - Squared = 81 !!
Le résultat obtenu ne diffère pas de ce qu’on aurait eu s’il y avait déclaration et raccord des étages unité par unité (sans recours au regroupement par modules).
L’important avantage apporté par cette technique est qu’il est désormais possible de regrouper plusieurs traitements répartis sur un nombre illimité de sous étages puis d’exposer l’étage résultant sous la forme d’une entité Source, Flow ou Sink.
Il suffira par la suite de raccorder le tout avec les bons appels méthodes (via et to) sans exposer le comportement intrinsèque de l’étage composé.
De plus, grâce au Materializer un étage composé ne sera réellement concrétisé que lorsqu’on appelle effectivement la méthode run.
Donc un étage, simple ou composé, représente uniquement une sorte de plan descriptif du mode de fonctionnement et non pas le fonctionnement en soi.
C’est-à-dire qu’à chaque fois qu’on effectue une matérialisation concrète, on obtient une exécution nouvelle non liée aux autres exécutions émanant du même étage.
En conséquence de tout cela, on pourra exporter les étages composés vers d’autres utilisateurs de façon complètement transparente les rendant de la sorte portables et partageables.
Récapitulons l’essentiel de la composition avec l’illustration suivante :
- Notes générales sur
Scala- La syntaxe de déclaration d’une méthode ou fonction nommée
fooFuncacceptant une liste de paramètre a de type A, b de type B, c de type C …etc et retournant un résultat de type R est comme suit :<strong>def</strong> fooFunc <strong>(</strong>a<strong>:</strong>A<strong>,</strong> b<strong>:</strong>B<strong>,</strong> c<strong>:</strong>C<strong>)</strongstrong>:</strong> R <strong>=</strongstrong>{</strong> ... <strong>}</strong>
Il est possible d’omettre l’expression du type de retour: Rétant donné que le compilateurScaladispose aussi pour les méthodes et fonctions d’un mécanisme d’inférence de type. - Dans le corps de la méthode/fonction il est possible d’omettre le mot clé
returncar le compilateurScalaretourne par défaut le résultat de la dernière expression.
C’est pour cette raison que lors du dernier code snippet on n’a pas utilisé d’expression avecreturnpuisqu’on retourne directement l’objet construit. - Lorsque la méthode/fonction déclarée ne contient qu’une seule expression on peut omettre les accolades
{et}délimitant son corps.
Appliquées à la fonctionsquareSourcede l’exemple précédent, ces règles conduisent à cette réécriture de la fonction (sans type de retour, sans accolades) :<strong>def</strong> squareSource<strong>(</strong>intSeq : Seq[Int]) <strong>=</strong> Source[Int](intSeq).via(Flow[Int].map(i => i * i))
- La syntaxe de déclaration d’une méthode ou fonction nommée
Récapitulatif partie 2
Voilà ! 😃
On arrive à la fin de ce deuxième blog post de la série dans lequel on avait premièrement défini la structure de notre projet, puis présenté le modèle système d’acteur et enfin exploré l’architecture de base de Akka Streams et sa propriété de modularité et composition.
Dans la troisième et dernière partie de notre série, on va se rapprocher du concret avec un cas d’utilisation plus tangible : une manipulation sur du contenu d’un fichier.
© SOAT
Toute reproduction interdite sans autorisation de la société SOAT