
Tout savoir sur Mage.AI

- Pour s’intéresser à Mage.AI
- La communauté Mage.AI
- L’interface de développement
- La prise en main de l’outil
- Les bonnes pratiques
- Retours d’expérience
Auto-proclamée comme le remplaçant moderne d’Airflow, Mage.ai permet de développer, déployer et monitorer des pipelines data (ou flux de données). La plateforme, créée en 2022 et dont le code est open-source, cumule 5k étoiles sur GitHub. Le projet jouit d’une belle dynamique, en atteste le support reçu par des personnalités de la sphère data engineering comme Zach Wilson ou Benjamin Rogojan, ou encore ce récent sondage de Marc Lamberti qui positionne Mage comme la première plateforme que la communauté veut tester.
Le développement repose sur la notion de block (ou composant), un bout de code, qui va se connecter à d’autres blocks pour former le pipeline. L’environnement de développement repose sur un serveur Jupyter et chaque cellule du notebook constitue un composant. Le développement peut se réaliser en Python, R, SQL et la sortie d’un composant est alors récupérable par un autre.
Les deux principaux avantages de démarrer avec Mage :
- ✅ Qualité des données : Chaque sortie est analysable durant le cycle de développement du pipeline et le test de ses données est réalisable directement dans le composant.
- ⚡ Rapidité du développement : La création d’un composant automatiquement alimenter la bibliothèque. Celle-ci étant partagée par l’ensemble des pipelines du projet, les composants sont réutilisables par l’ensemble de développeurs.
La plateforme permet également le déploiement et l’activation des pipelines, sous forme d’API, d’évènements, ou de tâches programmées. Une fois la partie déploiement terminée, il est alors possible de monitorer l’état des runs (lancement de pipelines).
Pourquoi s’intéresser à MAGE.AI ?
Pour comprendre l’intérêt de Mage dans l’écosystème des outils d’orchestration, il faut le comparer aux solutions existantes. A ce titre, Mage.ai se positionne comme un remplaçant moderne d’Airflow. Mais pourquoi ?
- Dans un premier temps, Mage vous permet de développer directement depuis la plateforme, contrairement à Airflow qui nécessite un moyen plus classique comme un environnement de développement intégré (IDE).
- À l’instar d’Airflow, il est possible de brancher un Git sur le projet Mage. En faisant cela, le versionning s’appliquera aux composants et flux. Pour Airflow, le dossier de diagramme acyclique dirigé (DAGs) sera versionné.
- Airflow a besoin d’un tiers pour faire de la validation de données, qui peut passer par Great Expectation par exemple. Cela est également possible dans Mage.ai mais celui-ci propose nativement ce type de mécanisme de contrôle.
- Durant le développement, vous n’avez pas à développer un script Python entier qui va s’occuper de lancer les tâches, c’est à dire un DAG. Vous allez développer directement le code que vous souhaitez lancer, qu’il soit en Python, R ou encore SQL. Mage prend en charge l’orchestration des tâches lors du lancement.
- Mage alimente la visualisation du flux automatiquement à l’ajout de code, permettant de garantir l’accord avec la conceptualisation. Airflow a besoin qu’on lui charge le script pour pouvoir l’interpréter de manière visuelle.
- Mage permet au data engineer de déployer les pipelines sous forme d’API REST, tout comme Airflow s’il est paramétré pour. Contrairement à cet article qui illustre la manière de faire et d’appeler l’API avec Airflow, Mage propose ce déploiement en un instant avec un endpoint dédié à votre pipeline.
- Mage favorise la collaboration sur les pipelines. Comme le projet fonctionne en mode plateforme, chaque développeur peut venir améliorer ou alimenter les pipelines.
- Enfin, comme abordé plus haut dans l’introduction, le développement des pipelines peut être accéléré par l’import des blocks depuis la bibliothèque ou l’utilisation des templates de code disponibles dans la bibliothèque.
La communauté Mage.ai
La communauté Mage.ai totalise plus de 2 300 membres sur le Slack officiel. On y retrouve notamment les développeurs de la plateforme qui sont à l’écoute de leurs utilisateurs et apportent souvent des améliorations. Sur LinkedIn, le nombre d’abonnés s’élève à plus de 12 000 et comprend des personnalités de la data engineering comme Zach Wilson et Benjamin Rogojan.
Depuis l’ouverture du code en 2022 sur GitHub, ce sont plus de 5 000 étoiles qui ont été apportées par les utilisateurs et 400 d’entre eux iront jusqu’à faire leur fork du projet. Quant à l’équipe de contributeurs, ce sont 39 personnes qui œuvrent à l’amélioration de l’outil.
L’interface de développement
La bibliothèque héberge les blocks du pipeline selon leur catégorie : chargement, traitement, senseur. Il permet également d’accéder à des fichiers de configuration du projet comme le requirement.txt, pour pip, ou encore le io_config.yaml qui permet de se connecter aux bases de données. Cette bibliothèque contient également les pipelines du projet.
Le notebook est l’espace de développement. Un composant est identifié selon la tâche qu’elle accomplit. Il peut donc soit être identifié comme chargement, transformation ou export, etc. Un nom doit ensuite lui être attribué.
Les modules remplissent des fonctionnalités diverses. Vous pouvez : visualiser les étapes durant le développement ; visualiser les données sous forme tabulaire ou graphique ; ajouter des secrets pour votre projet ; ajouter des variables d’environnement pour votre pipeline ; accéder au terminal de la machine hôte.
La prise en main de l’outil
Comment accélérer le développement de nos pipelines et s’assurer de la qualité des données dans un contexte open-data ?
Nous avons travaillé avec des données d’entreprises issues de l’open data. Deux pipelines ont été développés :
- le premier permettant de récolter des données à partir d’une liste de SIRET et de filtrer ces données;
- le second permettant de récolter les SIRET à partir d’un jeu de données d’entreprises du réseau French Tech.
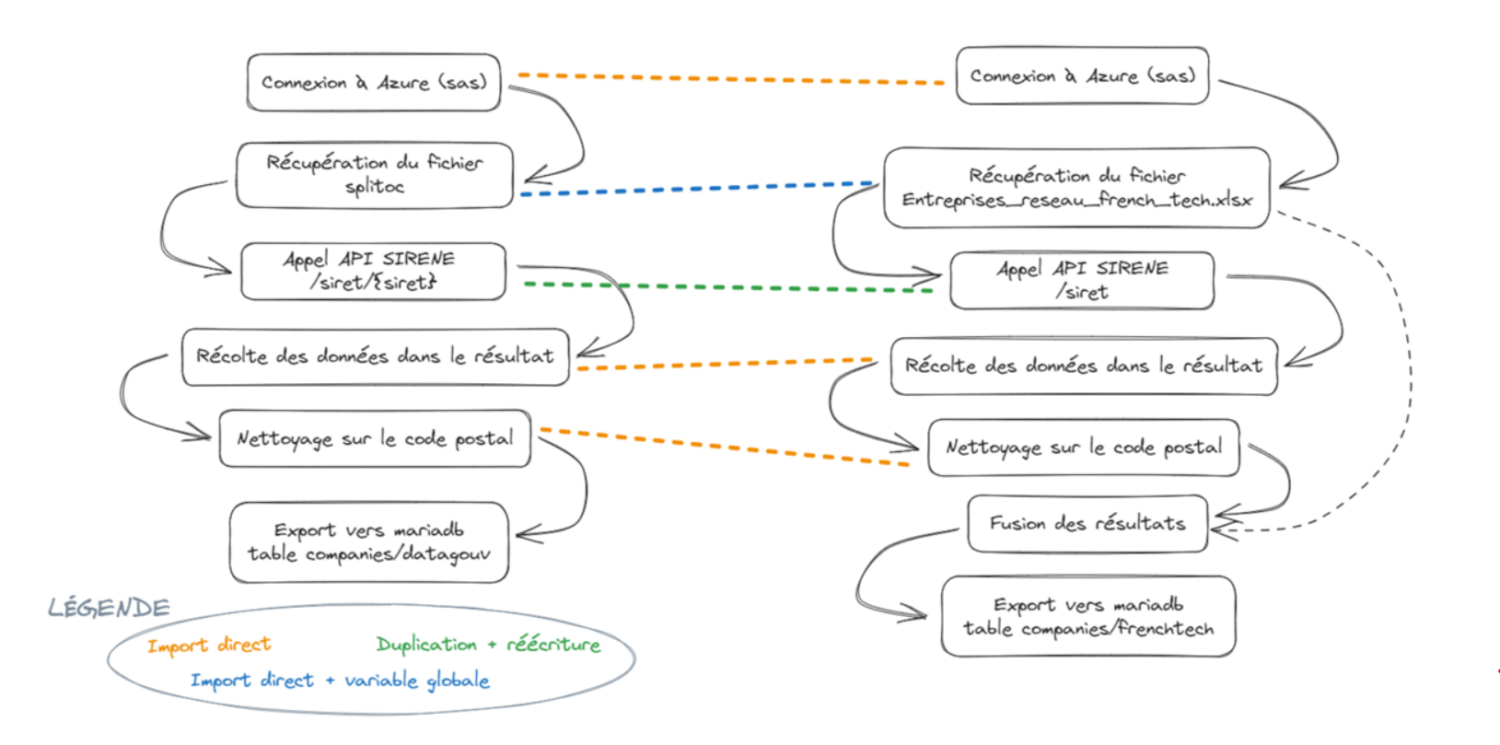
Pipeline n°1 – Récolte de données à partir du SIRET
Pour ce premier pipeline, appelé datagouv, nous partons d’un fichier contenant des données issues du site data.gouv.fr (disponible ici). Nous récoltons des données issues de l’API SIRENE pour chaque SIRET de notre tableau. De ces résultats, nous en gardons une partie et supprimons ceux qui n’ont pas de code postal. Le tout est chargé dans une base MariaDB.
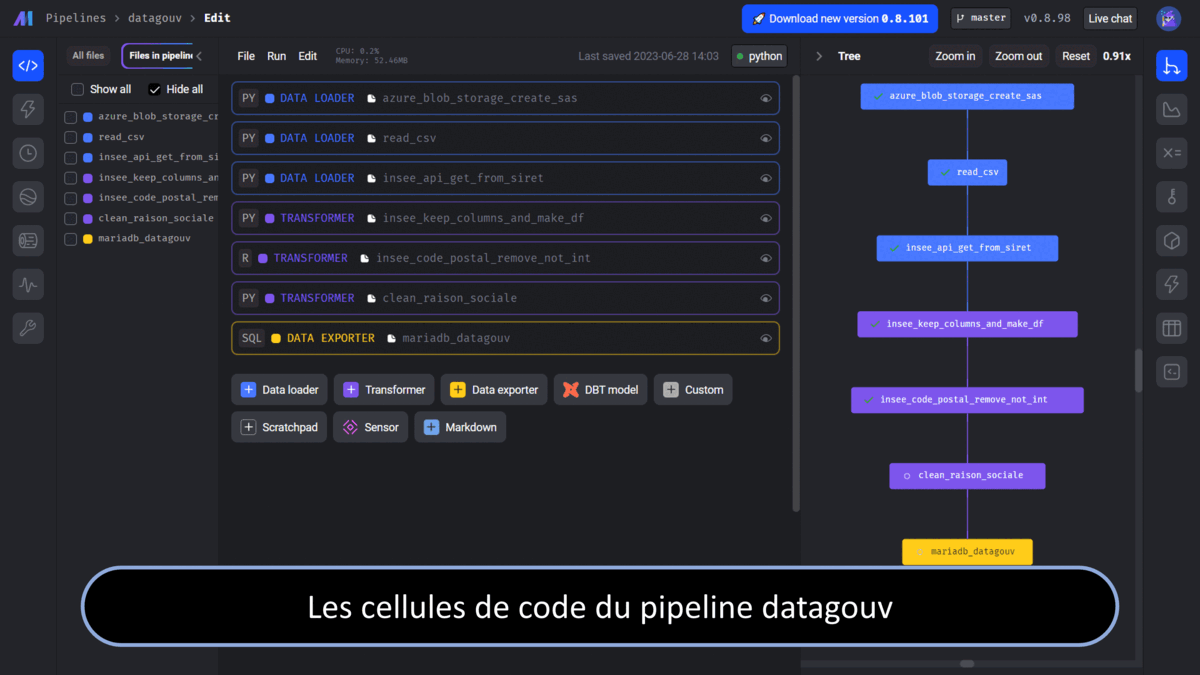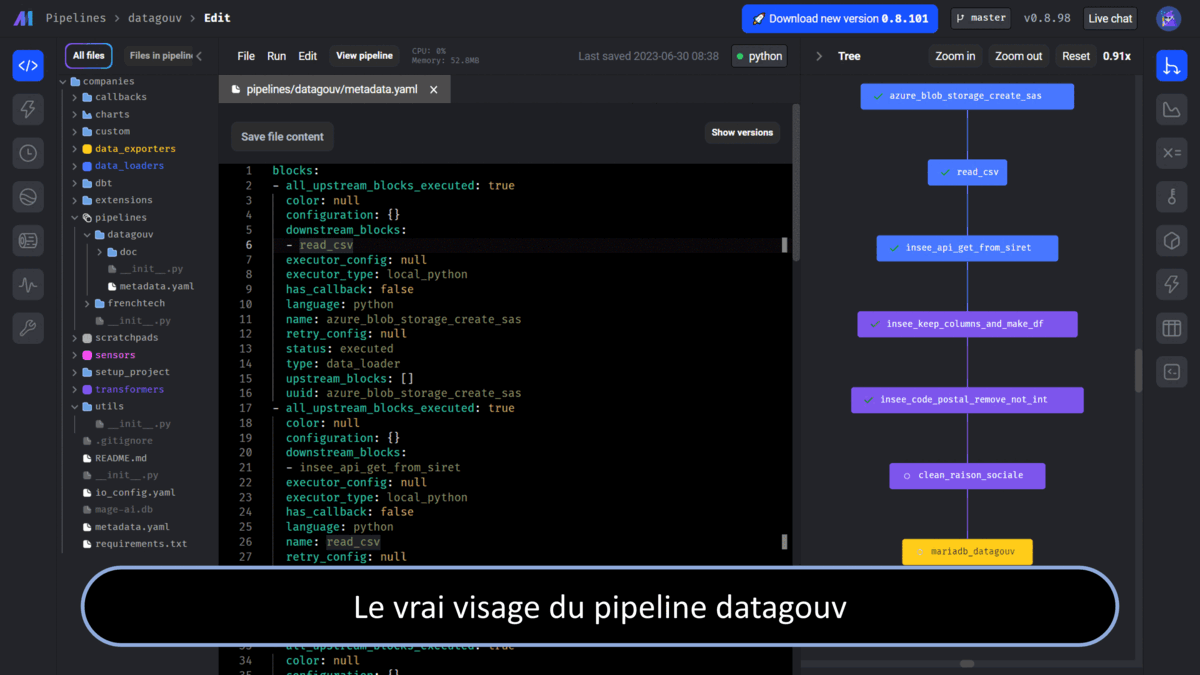
La principale difficulté a été de construire le block de récupération de notre fichier sur notre Azure Blob Storage (ABS). En effet, au moment ou nous écrivons cet article, le template pour accéder à l’ABS n’est pas documenté. Étant donné que l’accès au fichier nécessite la création d’une url d’autorisation, nous avons choisi de développer une construction automatique d’url à l’aide d’une variable d’environnement spécifique au flux. L’url sera ensuite digérée par pandas pour lire le fichier, en l’occurrence un csv.
Nos SIRETs sont ensuite envoyés à SIRENE pour récupérer les informations de ces entreprises. Certains champs sont gardés puis les résultats qui n’ont pas de code postal sont supprimés. La première transformation est réalisée en Python et la seconde en R. Enfin, du code SQL charge les données dans notre base de données MariaDB.
Pipeline n°2 – Récolte de données INSEE à partir d’une Raison Sociale
Pour notre second pipeline, appelé frenchtech, nous allons cette fois récolter des données de l’API SIRENE en envoyant la raison sociale d’entreprise du réseau French Tech. En effet, dans notre jeu de données de départ, nous avons trop d’informations ainsi qu’une absence de SIRET.
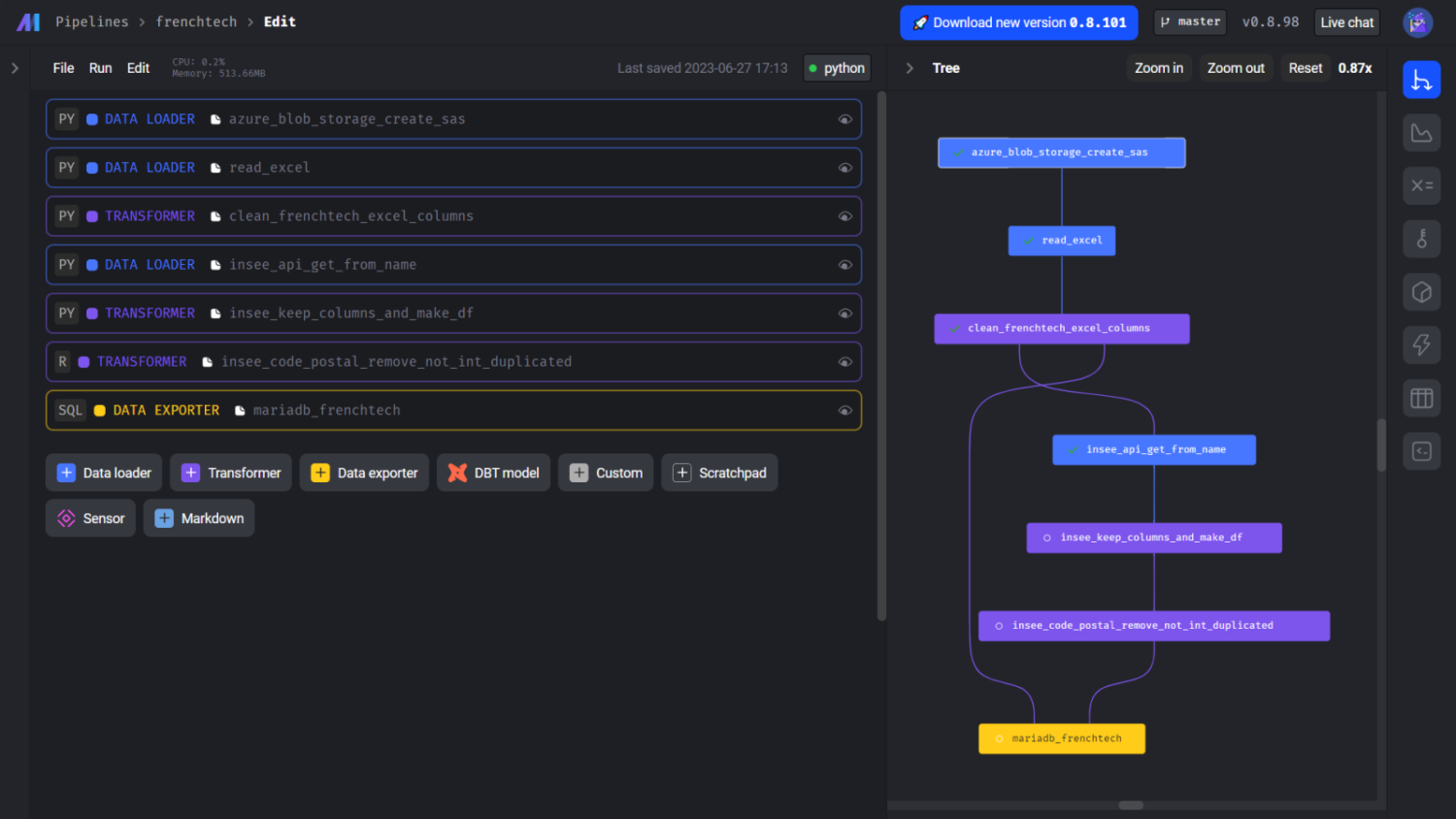
Comme le fichier que nous souhaitons récupérer est également sur Azure, nous allons gagner du temps en important le bloc que nous avons développé dans notre premier flux. Pour rappel, le nom du fichier à récupérer est stocké dans une variable d’environnement, le nom étant différent entre datagouv et frenchtech.
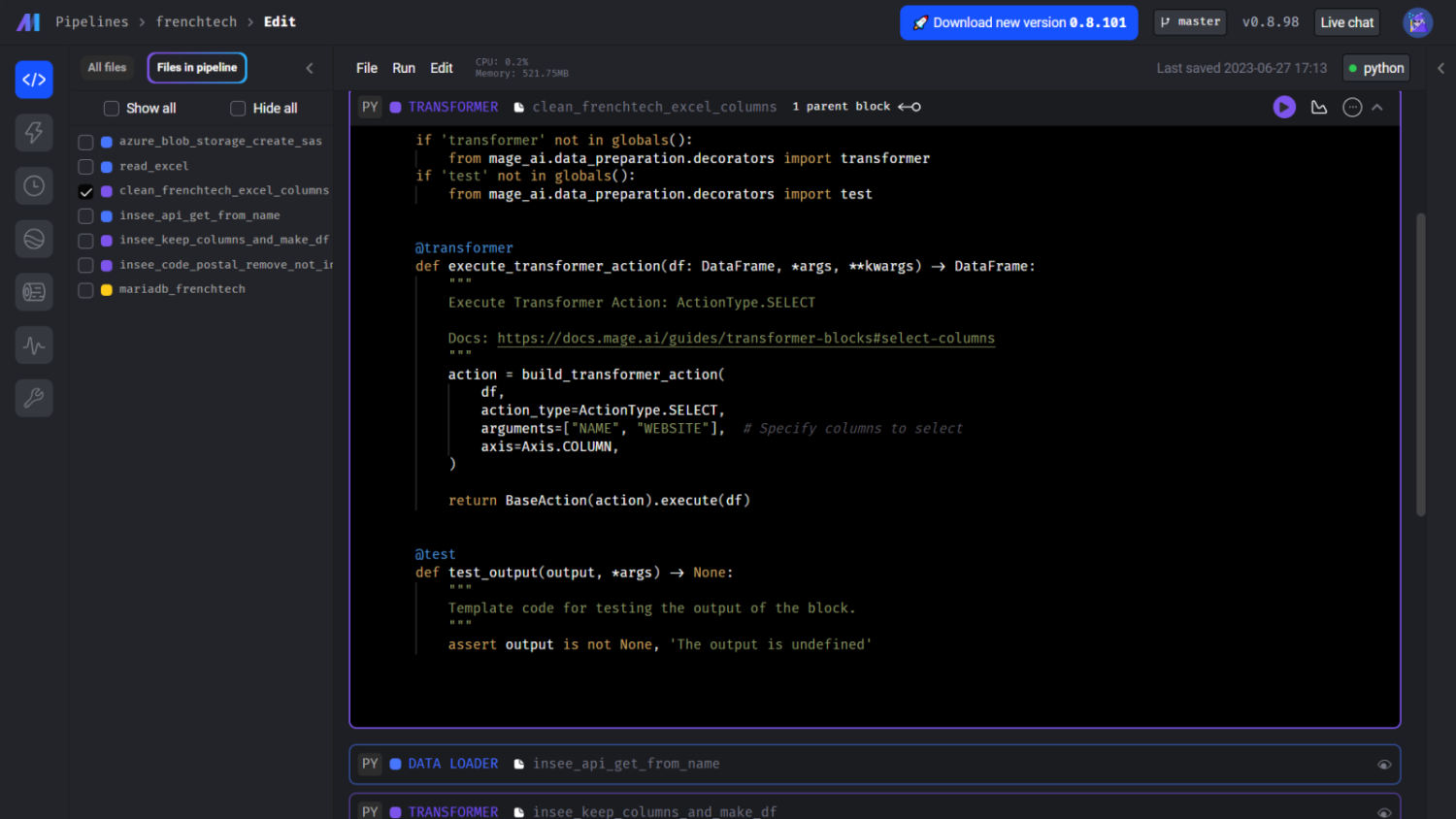
Nous allons par la suite envoyer la raison sociale de chaque entreprise du tableau. Pour cela, nous nous sommes appuyés sur le travail réalisé dans datagouv pour l’appel API, en dupliquant le composant et en l’ajustant. Comme nous souhaitions récupérer les mêmes informations et appliquer le même filtre pour le code postal que pour datagouv, nous avons simplement importé les deux blocks. Vous remarquerez que sur le pipeline, il est indiqué que le block R est issu d’une duplication. Cela est dû à un problème d’import spécifique à notre version de Mage dont le bug est en cours de fix.
Nous allons ensuite charger les données dans une table dédiée à frenchtech. Nos données sont issues de deux composants différents, avec deux langages différents. Or cela ne complique pas la dernière étape du pipeline puisque la jointure entre ces deux jeux de données va se faire directement dans le code SQL.
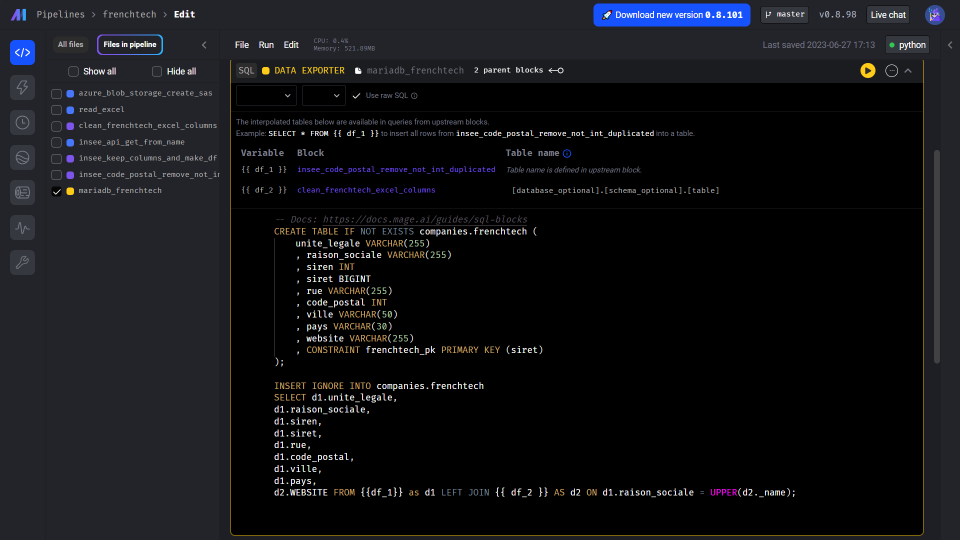
Orchestration des pipelines
Nos deux pipelines sont prêts et cohérents avec la conceptualisation, nous pouvons passer à l’étape d’orchestration !
Le premier sera lancé toutes les heures puisqu’il charge en base 200 entreprises issues d’un échantillonnage aléatoire des 75 000 SIRETs. Le second sera lancé en tant que service puisqu’il traite un fichier entier.

Nos bonnes pratiques
Si vous souhaitez commencer à travailler avec Mage, nous avons dressé pour vous une liste de bonnes pratiques pour optimiser votre expérience utilisateur :
- Versionnez votre projet. C’est une évidence mais il est important de le rappeler.
- Profitez de la possibilité de brancher un Git sur votre instance Mage. Réservez-vous une instance Mage qui pointera vers un répertoire Git cloné sur une branche de développement et une autre instance Mage qui va pointer vers le même répertoire cloné autre part et branché sur la branche principale. Votre deuxième Mage servira de prod et lancera les flux via les triggers.
- Documentez vos pipelines. Que ce soit sur le fonctionnement même de celui-ci au travers des blocks markdowns ou en utilisant une issue pour traquer le développement ou les difficultés rencontrées. Dans notre PoC, nous étions en méthode 1 pipeline= 1 issue et pour les suggestions de blocks en méthode 1 block = 1 issue. Veillez à utiliser un tag, comme [pipeline] ou [block] dans votre titre ou utiliser la fonctionnalité de tag de votre plateforme de versioning.
- Soyez explicite dans le nom de vos blocks. Cela permettra à vos data engineers de ne pas perdre de temps de recherche dans la bibliothèque.
- Développez en équipe. Mage vous permet de modifier le code de votre équipe pour apporter votre aide ou votre expertise sur un développement en particulier alors profitez-en.
- Pensez réutilisabilité lors du développement d’un block. Faites gagner du temps à votre équipe en leur permettant d’exploiter le potentiel de la bibliothèque.
- Utilisez la représentation visuelle du flux pour vous assurer des étapes.
- La création de graphiques est très facile. Capitalisez dessus pour identifier vos axes de développement.
Nos retours d’expérience
« J’ai découvert Mage en août 2022, et je suis plus que ravi d’avoir participé à cette expérimentation. J’ai très vite accroché à l’interface simple et le notebook m’a rappelé mes débuts en data. Le développement des pipelines s’est fait très rapidement, sans avoir à comprendre complétement le fonctionnement de Mage lui même. Je ne vais pas suivre les critiques faites sur Airflow puisque j’estime que l’outil mérite sa place de leader du marché de l’orchestration open-source. Toutefois, ce n’est pas exactement sur ce marché que je positionnerais Mage, qui est plus concentré sur l’expérience utilisateur durant le développement. Je pense que les deux sont compatibles dans le sens où l’on peut développer avec Mage et faire migrer ses pipelines sur Airflow pour orchestration.”
Kyllian, Data Engineer au sein du service innovation et de la practice data
“Après une expérience professionnelle sur Airflow dans une équipe qui s’est auto formée, le premier point qui m’a sauté aux yeux en essayant Mage, est la documentation et la communauté très accessible. Quand sur Airflow, entre les versions, les librairies obsolètes et une documentation, à mes yeux, pas optimisée, nous pouvions mettre des heures à trouver une solution à notre problème, sur Mage je n’ai pas rencontré ce type de difficulté. Par exemple, les opérateurs S3 (S3BucketOperators) dans Airflow, nous ont posé pas mal de soucis dans leur utilisation ainsi que lors des montées de versions d’Airflow (changement d’emplacement de la librairie). D’autre part, leur gestion des dags et des tags selon les versions d’Airflow ainsi que leurs appels de tâches en fin de dags ne m’ont pas paru instinctifs du tout. En somme, j’étais ouverte à la découverte d’une solution pour remplacer cet outil que je trouvais efficace mais peu agréable d’utilisation et de développement.
Côté Mage, l’outil est encore très jeune, selon les versions nous avons pu rencontrer des bugs mineurs de la plateforme comme les changements de noms des pipelines ou plus majeurs comme l’impossibilité de modification (ni de sauvegarde) si une autre personne vient sur la page de votre pipeline. Mais nous ne sommes même pas encore à la version 1, la bêta est très prometteuse, les développeurs très réactifs. C’était un plaisir d’essayer un outil pensé à ce point pour sa facilité d’utilisation et son ergonomie qui le rend vraiment très agréable à utiliser. La réutilisation des blocs, la visualisation de la donnée au fur et à mesure du développement, les multiples possibilités de développement d’une fonctionnalité, du SQL au R en passant par le Python, il y en a pour toutes les logiques et tous les goûts.
Avec une lancée pareille, j’ai hâte de mettre Airflow derrière moi.”
Clémentine, Data Engineer au sein de la pratice data
Et plus globalement sur la plateforme MAGE.AI :
- Les plus
Le développement est agréable. Nous n’avons qu’à nous concentrer sur le code des blocks. La partie construction du pipeline est gérée automatiquement dès l’ajout d’un block. Il est aussi très facile de déplacer un des composants dans le pipeline, ou de changer de parent.
La technologie du notebook permet de voir rapidement quelles données sortent de notre block.
La plateforme est facile à mettre à jour. En passant par docker, il est possible de déporter la base de données pour le fonctionnement de Mage (utilisateurs, secrets, etc.) dans un volume, éteindre votre Mage, et construire l’image avec la nouvelle version en pointant vers votre volume.
Le data engineer peut s’assurer de la qualité de ses données grâce aux fonctions de test dans les blocks. Et si cela n’est pas assez, il est facile d’ajouter une brique dédiée comme Great Expectation.
La possibilité de déployer son pipeline sous forme d’API enlève une partie peu intéressante pour le data engineer. Le paramétrage des triggers est également très facile.
- Les axes d’amélioration
La notion de test de données est réservée aux composants Python. Cela limite la modularité de l’outil au niveau de la construction des blocks.
Il manque la possibilité de voir le niveau de partage d’un block entre les pipelines d’un projet. Cela permettrait de mesurer les impacts en cas de changement et d’en évaluer le niveau de criticité.
Le développement d’un block doit se faire sans auto-complétion intelligente. Cela est perturbant lorsque nous sommes habitués à avoir ce genre de fonctionnalité sur des IDE comme Visual Studio Code. L’auto-complétion est proposée par rapport au texte déjà écrit sur le block, ce qui la rend presque inutilisable car pertinente seulement pour les noms de variables que l’on veut rappeler.
Les blocks qui ne sont pas utilisés par des pipelines restent dans la bibliothèque. Cela peut rendre tentaculaires les dossiers de votre projet.
Il y a un décalage entre la documentation et la plateforme, comme l’exemple cité plus haut avec un template pour l’Azure Blob Storage disponible à l’utilisation mais sans documentation ou explication associée.