
Tests, bugs & rock’n’roll…
 Pourquoi les fins de projet sont-elles toujours aussi « rock’n’roll » ??! Les méthodologies classiques de développements ont échoué…
Pourquoi les fins de projet sont-elles toujours aussi « rock’n’roll » ??! Les méthodologies classiques de développements ont échoué…
Cet article, est bien plus que le rapport d’autopsie d’un « n » ème projet qui a mal fini… il tentera d’analyser pour vous, développeurs, les raisons de l’échec, et parviendra à vous convaincre j’en suis sûr, de tester une nouvelle eXPérience…
Avant propos
Ami développeur bonjour ! Oui, cet article s’adresse à toi, développeur, quelle que soit ta techno préférée… java, .NET, C++ ou autre, nous allons parler méthodologie de tests, et en particulier tests unitaires…
J’entends d’ici venir tes protestations « je ne suis pas testeur, je suis développeur, alors en quoi cet article me concerne-t-il ?? Et de toute façon, les tests ça m’a toujours gonflé… D’ailleurs ça a toujours gonflé n’importe quel développeur, ce n’est pas un boulot de « techos »… Des tests, moins j’en ferai, mieux je me porterai… »
Ca te rappelle quelqu’un ?
« Et pourquoi je devrais faire des tests puisque mes développements seront au final testés lors de l’intégration, et même lors de la recette fonctionnelle par la maîtrise d’ouvrage ? Rien à faire, non seulement ça me gonfle, mais en plus ça ne sert rien, c’est une perte de temps ! »
Qui n’a jamais pensé ça…
« Et même si je voulais tester mes dev, avec la meilleure volonté – où la meilleur pression du chef de projet du monde – je ne peux pas ! Impossible de faire un test sur le composant que j’ai développé sans les inputs fournis par les autres modules, il y a trop de dépendances ! »
Là, peut-être, tu te dis que ça te rappelle des souvenirs !
« Et même si je le voulais, et que je le pouvais, je n’ai matériellement pas le temps, les plannings sont trop serrés : mes développements sont à peine terminés quand doit commencer l’intégration… Quand pourrais-je faire ces tests unitaires !? »
Si tu es toujours là, je t’encourage vivement à poursuivre ta lecture jusqu’au bout…Tu n’apprendras sûrement pas ici, en 5 minutes, à la simple lecture ce post, le « comment » des tests ; mais si tu finis par relever la tête en étant convaincu du « pourquoi », on pourra considérer que le plus gros du travail est fait !
 Projet Foo : une course contre la montre
Projet Foo : une course contre la montre

Bob est un développeur lambda, pas vraiment junior, pas non plus senior, Il va intervenir sur le projet Foo qui doit se dérouler suivant le schéma classique du « cycle en V ». Un planning a été établi suite à l’expression de besoin du client, il doit participer au projet pour travailler sur les phases de développements/tests.
 Bob est content de commencer sur ce projet. Il aime développer, et c’est exactement ce qu’il va faire sur le projet Foo. Par contre, il n’a jamais vraiment compris à quoi servait ce rectangle sur le planning, où sont écrits « Tests unitaires »… Il aime expliquer à ses collègues, non sans une certaine ironie, que ça doit être une tradition dans les développements « cycles en V », pour que les 2 branches du V soient bien symétriques ! Peu importe, ces 2 semaines de tests unitaires, ça ne fera jamais que 2 semaines en sus pour fignoler les développements…
Bob est content de commencer sur ce projet. Il aime développer, et c’est exactement ce qu’il va faire sur le projet Foo. Par contre, il n’a jamais vraiment compris à quoi servait ce rectangle sur le planning, où sont écrits « Tests unitaires »… Il aime expliquer à ses collègues, non sans une certaine ironie, que ça doit être une tradition dans les développements « cycles en V », pour que les 2 branches du V soient bien symétriques ! Peu importe, ces 2 semaines de tests unitaires, ça ne fera jamais que 2 semaines en sus pour fignoler les développements…
Bob part confiant sur ce projet. Il connaît assez bien la techno utilisée. D’autant plus qu’il n’y a pas de réelles difficultés techniques, c’est une application de gestion classique, les « use cases » sont bien spécifiés, il n’y a pas de raison que ça se passe mal !
Il attaque donc avec entrain sa première classe, puis la deuxième, et la troisième… Tout va bien, ça compile, on continue. Les jours passent, la deadline se rapproche, il va falloir donner un petit coup d’accélérateur sur la fin pour tenir les délais avant l’intégration, mais ça va aller. Bob a finalement réussi à terminer les développements – « une bonne chose de faite » – il va pouvoir commencer l’intégration et les tests d’intégration…
Bob démarre le programme principal, mais rien ne s’affiche… pas d’erreur dans les logs, étrange. Bob dégaine alors son debugger, et commence une exécution en mode pas à pas. « Mmmh, pourquoi ce pointeur est-il null à cet endroit-là ? C’est impossible, mon contexte aurait déjà dû être initialisé à ce moment de l’exécution, il faut que je revienne en arrière jusqu’à trouver où et pourquoi l’initialisation ne s’est pas faite, corriger le problème et améliorer cette gestion d’erreur… »
Commence alors une longue traque à travers le code (à reculons…). Il est 23h, Bob a fini par trouver l’origine de son erreur (et a corrigé par la même occasion toute une tripotée de bugs)… Mais toujours rien ne s’affiche ! « je ne comprends pas, ça n’a aucun sens, c’est impossible, je ne comprends pas d’où vient le problème ! » Bob est épuisé par sa journée de debugging (1), il a mal au crâne et rentre chez lui frustré par sa journée et par les problèmes qui l’attendent le lendemain.
(1) Chacun sait, pour s’y être confronté au moins une fois dans sa vie de développeur, à quel point l’épreuve du « debu(r)gger de la mort » est difficile… Retrouver en une soirée une longue série de bugs sur un programme « fini » censé fonctionner…

Bob passe une autre journée de debugging, il est fatigué et démotivé. Il parvient enfin à faire s’afficher son écran et attaque, maugréant, les tests sur un autre cas d’utilisation. Ô surprise, ça ne marche pas non plus, c’est reparti pour une journée de debugging dans des classes codées des mois auparavant. « Pourquoi j’ai codé ça comme ça ? C’est n’importe quoi !! On va refaire ça autrement pour corriger le problème… »
Bob est stressé et démotivé. C’est en général dans ces moments-là que le sort s’acharne. Le chef de Bob passe le voir pour lui remonter un problème qu’il a détecté en faisant quelques tests au hasard : « là, le premier écran de s’affiche pas. Tu peux regarder ? » Bob ne comprend pas. « J’ai déjà eu ce problème, je l’ai corrigé la semaine dernière !!! »
Bob est de plus en plus fatigué et frustré par son travail. Chaque correction qu’il apporte crée autant de nouveaux bugs, il ne compte plus les régressions et doit faire en moyenne 3 fois les mêmes tests sur toute la durée de la phase d’intégration. La recette aurait déjà dû commencer, la phase d’intégration a pris beaucoup plus de temps que prévu, et le code est à présent devenu compliqué, fragile, peu fiable, et difficile à maintenir. L’application est de médiocre qualité, sera livré avec beaucoup de retard, Bob a sacrifié toutes ses soirées pour le projet, il est épuisé et frustré et son travail apparaît comme médiocre pour son chef de projet qui ne lui fera part d’aucune gratitude.

Où et pourquoi ça a dérapé ?
Bob a fait face à un « cuisant » échec sur le projet Foo. Peut-on dire qu’il est incompétent ? Qu’il ne s’est pas donné les moyens de la réussite ? Non, Bob maîtrisait sa techno et n’a pas compté ses heures… Il a même sacrifié ses soirées pour que le travail soit fait en temps et en heure ! Alors quel est le problème de Bob ?
1. Le dérapage, caméra embarquée
A quand remonte la perte de contrôle entraînant la sortie de route ? Les choses ont commencé à mal tourner lors de l’intégration : cette phase aurait-elle été sous-estimée ? Le planning était-il trop optimiste ?
C’est en tout cas ce qu’il en ressort si l’on imagine l’évolution du « niveau de confiance » de Bob sur la réussite du projet tout au long de son déroulement :
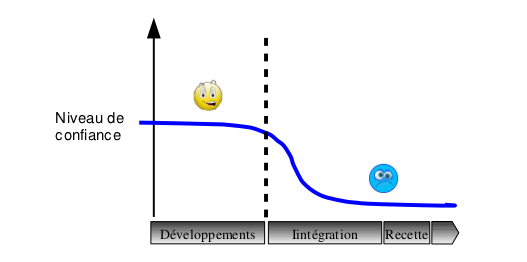 Bob a été confiant sur toute la phase de développement, car il mesurait son avancement à la quantité de classes codées, et que ce travail avançait à bon rythme. Sa confiance chute brutalement au début des tests d’intégration… plutôt laborieux (nombreux bugs à corriger, nombreuses régressions)
Bob a été confiant sur toute la phase de développement, car il mesurait son avancement à la quantité de classes codées, et que ce travail avançait à bon rythme. Sa confiance chute brutalement au début des tests d’intégration… plutôt laborieux (nombreux bugs à corriger, nombreuses régressions)
Mais cette confiance pendant la phase de développements était-elle justifiée ? Bob n’était-il pas déjà dans le rouge sans le savoir ?
2. Le ralenti, caméra fixe
Ce « niveau de confiance » est un indicateur trop subjectif. Essayons plutôt de considérer des faits plus objectifs. Ce qui est sûr, c’est que :
- plus il y a de lignes de code, plus il y a de bugs
- plus il y a de tests, moins il y a de bugs
- plus il y a de bugs, plus la réussite du projet est incertaine.
On pourrait alors estimer les risques de dérapages (ou niveau d’incertitude) sur chaque phase du projet, ce qui donnerait quelque chose comme ça :
 Le projet aurait alors potentiellement dérapé, non pas pendant l’intégration, mais dès la phase de développement ! Plus Bob a écrit de code, plus il a ajouté d’incertitudes et de bugs sur son composant…
Le projet aurait alors potentiellement dérapé, non pas pendant l’intégration, mais dès la phase de développement ! Plus Bob a écrit de code, plus il a ajouté d’incertitudes et de bugs sur son composant…
Ok, donc plus les développements avancent, plus le projet risque de mal finir : paradoxal non ? Alors que faire ? Une seule solution pour réduire l’incertitude : les tests. Super me direz-vous, c’est bien ce qu’a fait Bob pendant l’intégration, et ça ne lui a pas réussi… So what ??!
Maîtriser sa trajectoire
Bob a pêché par excès de confiance : c’est ici son unique défaut. En effet, il a attendu l’intégration pour commencer à tester son composant : il a considéré que tout ce qu’il a codé fait ce qu’il est supposé faire. Si l’on voulait faire une comparaison avec la construction d’un bâtiment, on pourrait dire que Bob a érigé un édifice, étage après étage, en ajoutant jour après jour un nouvel étage, sans jamais vérifier la solidité de l’étage monté la veille… Malheureusement, aussi compétant soit-il, Bob reste un être humain, faillible : Bob commet des erreurs !
Ne blâmons pas Bob, il est souvent interrompu dans son travail, parfois distrait, parfois stressé et sous pression, parfois fatigué… Il a mille et une bonnes raisons de faire des erreurs, ce n’est pas une machine. Ces erreurs ne sont pas forcément très graves, bien souvent, elles sont mêmes signalées par le compilateur. Cela dit, ce n’est pas parce qu’un programme compile qu’il fonctionne ! Ce qui manque à Bob, c’est un petit ange gardien, qui lui souffle à l’oreille à chaque bug qu’il est sur le point de coder « Attention malheureux ! Ca ne fera pas ce que tu crois !! ». Et si on l’appelait, ce petit ange gardien, un « test unitaire » ?
1. Faire plus de tests pour faire moins de tests
Des tests, Bob en a usé pendant l’intégration, et même abusé… Et malgré cela, il n’a pas réussi à éviter le dérapage. Pourquoi ? Parce qu’il a eu beau faire, refaire et rerefaire au moins 3 fois chaque test, il était déjà trop tard…
1.1 Faire plus de tests…
1.1.1 The sooner, the better
Il y a une règle dans tout projet, qu’il soit informatique ou non, qui dit :
« plus un problème est détecté tard, plus il coûtera cher à corriger ».
Imaginez, pour vous en convaincre, un maçon construisant un mur de briques. Il lui sera beaucoup plus facile de rectifier la verticalité de son mur s’il vérifie le niveau à chaque rangée de briques posée, plutôt que d’attendre la dernière rangée, sortir son niveau à bulle, son fil à plomb, un air dépité… et enfin une grosse masse.
Ce principe s’applique également à un programme informatique : si une classe est buggée, ou qu’elle est mal fichue, qu’il faut la refaire, ce sera beaucoup plus difficile et long une fois qu’elle est utilisée un peu partout !
Corollaire : plus un test est fait rapidement, plus la correction des bugs sera facile et rapide. Si l’on teste unitairement chaque classe juste après l’avoir codée, ce sera beaucoup moins pénible et plus rapide à corriger…
1.1.2 De la théorie à la pratique
Alors Bob ? Que se serait-il passé si tu avais commencé les tests dès le début des développements ?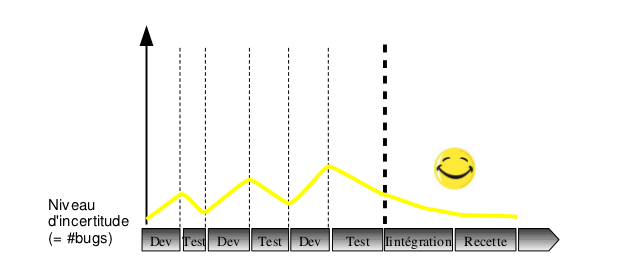 Les effets positifs :
Les effets positifs :
- Bob n’aurait pas laissé le nombre de bugs exploser ; il aurait évité les longues journées de debugging, passées à traquer de stupides erreurs… Il les aurait facilement débusqués et corrigés quasi en même temps qu’il les codait
- La phase d’intégration aurait été sensiblement raccourcie : le code intégré fonctionne déjà, le travail d’intégration est facile, il ne reste que très peu de corrections à apporter
- Bob aurait eu une bonne visibilité du « fait » et du « reste à faire » tout au long du projet : il sait ce qui est codé et ce qui marche (ce qui est testé). Pas de mauvaise surprise à l’intégration, pas de correction à la « va vite » qui crée autant de régression qu’elle ne corrige de problèmes. Conséquences :
- Il aurait pu prévoir bien avant l’intégration qu’il y aurait du retard, et alerter son chef de projet, qui aurait alors pu agir en conséquence (augmenter la taille de l’équipe de développement, préparer le client à un retard de livraison, « descoper »… Un travail de chef, quoi)
- il aurait subi moins de stress et de pression ! (il évite ainsi une calvitie précoce et une psychothérapie, et gagne un an d’espérance de vie)
Bon ok, les tests unitaires auraient permis de vivre le projet de façon plus sereine, d’avoir une meilleure visibilité sur les délais, d’améliorer la qualité du code et de raccourcir l’intégration. Mais ça n’a pas empêché Bob d’exploser malgré tous les délais : les tests unitaires, ça prend du temps…
Quel est le problème quand on fait les tests au fur et à mesure des développements, au lieu d’attendre que le code soit stabilisé pour commencer ? Chaque « itération » de tests devient de plus en plus longue, et ce pour 2 raisons :
- Plus les développements avancent, plus le programme devient complexe, plus il est difficile à tester
- Chaque fois qu’on rajoute du code, il faut refaire les tests qu’on a déjà faits, pour s’assurer qu’on n’a pas causé de régression
1.2 … En faisant moins de tests
1.2.1. Franchissement d’un torrent (de bits)
Bob, échaudé par le projet Foo et ses déboires, à la recherche d’une reconversion salvatrice, est affairé à la construction d’un pont suspendu, enjambant un fleuve sur une distance de 80m. L’ouvrage étant achevé, il est temps d’en éprouver la solidité. Bob commence alors à tester son ouvrage : il décide de faire franchir le pont à un train lancé à pleine vitesse, au moment où passe sous la construction une grosse péniche, naviguant à toute vapeur. L’acier craque, le pont se brise et s’effondre, la péniche coule emportée par les débris, le train est précipité dans le fleuve… Pas de panique, Bob est juste en pleine partie de Pontifex, la catastrophe restera virtuelle…

Qu’est-ce qui a causé l’effondrement de l’édifice ? Les remous causés par le passage de la péniche ? Le poids du train ? Le vent, les courants peut-être ?? Impossible à savoir, le test réalisé par Bob est trop « complexe » : il y a trop d’éléments testés en même temps : les fondations sous-marines des pylônes, la prise au vent du pont, la solidité des poutrelles d’acier ou des câbles de suspension…
Pour quelle autre raison peut-on dire que le test de Bob est totalement nul ? Imaginons un instant que le test ait été fait dans les mêmes conditions, mais un jour sans vent ? Le pont aurait pu tenir bon. Le test aurait alors indiqué que le pont est ok, à tort. Conclusion, le test de Bob ne prouve absolument pas la solidité du pont !
Et enfin, il est très difficile à faire : il lui aura fallu disposer de beaucoup de moyens pour réaliser son test (une péniche, un train, un fleuve…)
1.2.2. Retour aux sources
Un grand philosophe a dit un jour :
« On peut tester mille fois une classe, mais on ne peut pas tester une fois mille classes »
Je ne suis plus tout à fait sûr que c’était un grand philosophe, ni même s’il parlait de tests et de classes, ou de mensonges et de personnes ; l’important est l’interprétation que l’on veut en faire :
Plus un test couvre un périmètre large de code, plus il est difficile à faire et moins il éprouve le programme.
Revenons un instant sur le pont de Bob. Le test qu’il a réalisé est un mauvais test pour 3 raisons:
- il indique que le pont ne « fonctionne pas » sans plus de précision sur les causes
- dans le meilleur des cas, il peut uniquement nous dire qu’il existe certaines conditions avec lesquelles le pont « fonctionne »
- il coûte cher à réaliser
On rencontre les mêmes problèmes sur un projet informatique : exécuter un scénario complexe à travers l’interface utilisateur d’une application, pour tester, en une seule passe, l’IHM, l’intelligence métier, la couche de persistance (etc…) de l’application, c’est faire comme Bob et son test de pont :
- si le programme plante, il peut vite devenir difficile de trouver la source du problème. La conséquence directe est bien souvent une correction de « contournement » rapide au mauvais endroit, qui corrige effectivement le problème, mais qui engendrera combien d’effets de bord indésirables par la suite ? Sans parler de la qualité du code qui s’en ressent…
- si le programme ne plante pas, on a rien prouvé du tout. Si, on a prouvé que dans un contexte particulier, le programme fonctionne. Mais quid des 10 autres cas d’utilisation ? Plus il y a de composants en interaction les uns avec les autres, plus on multiplie les use cases… La question est : est-on seulement capable en manipulant l’IHM de parcourir tout le code que l’on croit tester ? (un grand classique : la personnalisation par profils utilisateur…)
- pour faire le test, on a du nécessairement passer beaucoup de temps à mettre en place un « contexte de test » (faire fonctionner un environnement de test complet : démarrer les applications dont le projet dépend, faire fonctionner les autres modules de l’application – que l’on n’utilise pas, mais sans lesquels l’application refuse de démarrer – et enfin, faire la saisie sur l’IHM du jeu de test – qu’il soit utilisé tout ou partie, dans notre simulation – …). En bref, plus un test couvre un large périmètre du programme, plus il coûte cher…
1.2.3. Frappes chirurgicales
Pour savoir pourquoi le pont de Bob n’a pas tenu, il aurait pu suffire de tester individuellement chaque composant du pont, avant de précipiter le train dans le vide :
- Les fondations sous-marines des pylônes résistent-elles aux courants ? Et si oui, jusqu’à quelles forces, et sous quel poids ?
- Quel effort subissent les pylônes avec le vent ? Sont-ils suffisamment solides ? Si oui, jusqu’à quelle force de vent ?
- Les poutrelles d’acier sont-elles suffisamment solides pour résister au poids d’un train ? Si oui, jusqu’à quel poids ?
- Idem pour les câbles de suspension ?
- Etc…
Ces premiers tests auraient permis d’éliminer de nombreux points de faiblesse dans la structure, des problèmes basiques ! De plus, ils n’auraient pas coûté très cher, mais auraient rapporté gros…
Vous l’avez compris, on peut continuer l’analogie avec un programme informatique : On se doit de tester individuellement les composants d’une application, avant de planter lamentablement le programme :
- Les classes de persistance (DAO…) peuvent-elles charger une entité ? Sauver une entité ? Rechercher des entités ? Si oui, qu’est-ce qui doit être renseigné dans une entité ? Quels critères de recherche sont obligatoires ? Peut-on sauver une entité qui existe déjà ?
- Les classes d’accès au modèle fonctionnent-elles ? Que se passe-t-il en cas d’accès concurrent ?
- La couche métier reflète-t-elle bien les processus métier ? Quelles entités peuvent être manipulées ? Les calculs donnent-ils des résultats exacts ?
- L’IHM fonctionne-t-elle ? Les fenêtres s’affichent-elles ? Se mettent-elles à jour ?
- Etc…
Plus les tests seront simples et ciblés, plus ils seront faciles à faire, et plus il sera facile de trouver les points de faiblesse ou les points de rupture du programme : « Keep It Simple and Stupid ! »
1.3 En bonus track
En résumé, ces tests nous ont apporté :
- un gage de fiabilité intéressant (ils ne coûtent pas cher mais permettent de corriger 90% des bugs)
- une aide précieuse à la correction des problèmes (les tests ciblent précisément les erreurs)
Mais ils nous apportent également, indirectement, des conséquences positives sur la qualité de l’application !
D’une part, faire un test unitaire nous oblige inconsciemment à nous poser les bonnes questions sur le composant testé :
- Que doit faire mon composant et que ne doit-il pas faire ?
- Quelles valeurs possibles puis-je obtenir quand je l’appelle ?
- Quelles valeurs ai-je le droit de fournir aux paramètres d’entrée ?
- Quelles sont les cas aux limites d’utilisation ?
Se poser ces questions, c’est définir le contrat d’interface du composant. Et définir ce contrat va doublement nous aider :
- pour implémenter correctement le composant, penser aux différents cas d’utilisation (nous faire penser à gérer les cas aux limites par exemple…)
- pour définir clairement le « mode d’emploi » du composant, et ses limites d’utilisation, et ainsi s’en servir correctement depuis un autre composant, éviter ainsi les bugs dus à une mauvaise utilisation !
Note : Certains eXtrémistes pousseront alors le vice jusqu’à écrire leurs tests avant le code… On parle alors de développements pilotés par les tests… Ces acrobates du moon walk en pas de java ont l’esprit bien tordu me direz-vous ; pas tant que ça : Si écrire les tests nous aide à définir le contrat d’interface du composant, alors pourquoi ne pas commencer par ça ?
D’autre part, une autre conséquence indirecte des tests unitaires est un meilleur design de classes de l’application. Pour écrire ces tests et être capables de les brancher sur les composants, nous allons devoir adopter un couplage faible entre nos composants, et ainsi éviter l’effet « plat de spaghetti » sur le code… Mais la seule façon de s’en convaincre, reste encore d’essayer et de constater…

2. Quelqu’un d’autre peut pas l’faire ?
Qu’y a-t-il de plus ennuyeux que de refaire ce qui a déjà été fait ? C’est le problème quand on « entrelace » les phases de développements et de tests : il faut sans cesse refaire les tests qui ont déjà été faits pour vérifier la non-régression de ce qui a déjà été validé… Faire, une fois, un test, a déjà, à la base, tendance à faciliter le transit intestinal du développeur lambda, mais s’il faut en plus le refaire et re-refaire…!!!
Alors, que fait le développeur quand un travail rébarbatif l’ennuie ? Il sort un framework de sa musette ! Et des frameworks de test, il en existe des tas… Les plus connus, Junit (java), Nunit (.NET), CppUnit (C++), PhpUnit (PHP) pour les tests unitaires. Avec ces frameworks, un test devient un programme à écrire, tout comme le reste du code(ce qui en passant a l’avantage de lui faire perdre une bonne partie de son caractère laxatif…)
Ok, donc faire un test, c’est coder un programme… Le gros avantage, c’est que repasser les tests devient tout de suite plus facile et rapide : il suffit de « lancer » les tests, comme on lance n’importe quel programme…
La non-régression est vite vérifiée, la machine le fait pour vous !
Le finish
Voilà, l’essentiel est dit… En résumé :
- Les tests unitaires ne coûtent pas cher et permettent de corriger 90% des bugs d’un programme (les 90% les plus stupides !)
- Pour qu’ils soient au maximum efficaces, et faciles à écrire, il faut les faire au fur et à mesure que les développements avancent (voire même, les écrire avant les développements)
- Des frameworks existent pour écrire ces tests, et faciliter la non-régression
- Faire des tests unitaires automatisés a une incidence positive sur la qualité et le design du code
- Avoir une bonne couverture de tests, c’est :
- s’assurer d’avoir des composants qui fonctionnent déjà à 90% avant l’intégration
- avoir une vision fiable de ce qui est fait et ce qui reste à faire
- c’est éviter le stress des régressions, des phases de tests qui n’en finissent pas, des bugs à répétition, et de devoir intervenir sur du code dont la qualité ne fait que se dégrader
Voici à présent ce qui n’a pas encore été dit dans cet article :
- Faire des tests unitaires automatiques tout au long des développements ne nous dispense PAS des tests d’intégration ! Ces derniers permettent de corriger les 10% de bugs qui ne sont pas remontés par les tests unitaires… Cela dit, ils seront grandement facilités et moins longs !
- Les tests unitaires sont un investissement qui facilite la maintenance future :
- car ils améliorent le design et la qualité du code
- mais aussi, parce qu’ils jouent le rôle de documentation technique (qui reste plus facilement à jour que toute autre documentation puisqu’elle est intégrée au code de l’application). Un test est un exemple d’utilisation du composant.
Le prix à payer n’est rien de plus que la maintenance de ces tests, au même titre que le code de l’application, tout au long de sa vie en exploitation.
En guise de conclusion, j’ajouterai qu’il est souvent difficile de réussir ses premiers tests… Pour pouvoir tester un morceau de code, il faut que le code ait été fait pour être testable (maîtrise des dépendances pour bouchonnage…). C’est une gymnastique pas forcément naturelle au départ ! Mais rassure-toi, pas non plus besoin d’un stage commando chez les moines shaolin pour apprendre ces techniques, il existe de nombreux articles et tutoriaux sur le sujet, qui permettent de comprendre les principes, et de mettre en pratique petit à petit… Un conseil pour commencer : d’abord frapper là où ça fait mal ! Quitte à prendre le temps d’écrire des tests unitaires, autant commencer par les composants les plus sensibles, les plus importants !
Faire les tests au fur et à mesure des développements prend alors tout son sens ! On peut à tout moment vérifier que le programme fonctionne, et progresser sereinement et en toute sécurité… Un doute sur les effets de bord induits par une modification apportée sur une classe ? Il suffit de relancer les tests pour être tout de suite fixé ! Un test échoue ? Le problème sera vite corrigé : le test qui échoue pointe du doigt le morceau de code qui a régressé…
Liens
Bon ok, faire des tests automatiques, utiliser des frameworks, faire tourner une usine de développement, tout ça a l’air cool, très fun, complètement fashion, voire atrocement tendance… Mais par quoi je commence, et comment ?
- Les ressources pour les frameworks de tests unitaires :
- https://www.regismedina.com/articles/fr/extreme-programming/pratiques/programmation : la mise en place de tests unitaires
- https://open.ncsu.edu/se/tutorials/junit/ : un rapide tutoriel sur l’utilisation de Junit sous Eclipse
- https://www.opensourcetutorials.com/tutorials/Server-Side-Coding/Java/java-unit-testing-with-mock-objects/ : un tutoriel sur les techniques de bouchonnage
… Maintenant, c’est à vous de jouer !