
Site Reliability Engineering : la clé de la fiabilité

Sommaire
- Introduction à la SRE (Site Reliability Engineering)
- La gestion du toil : améliorer la productivité
- L’observabilité
- Mesures, indicateurs et objectifs SRE
- SRE et DevOps : une synergie parfaite
- Conclusion

Introduction à la SRE (Site Reliability Engineering)
SRE signifie Site Reliability Engineering (ingénierie de fiabilité de site). Cette discipline incorpore certains aspects de l’ingénierie logicielle à la gestion des opérations informatiques afin d’obtenir des systèmes évolutifs et fiables. Le concept SRE a été popularisé en 2003 par Google lorsqu’ils ont décrit leur méthode de gestion des services à grande échelle.
L’objectif du SRE est de créer un équilibre entre la livraison de nouvelles fonctionnalités et la garantie d’une haute disponibilité, fiabilité et performance du service. Le principe fondamental du SRE est l’automatisation. Si une tâche opérationnelle est effectuée manuellement plusieurs fois (deux fois par exemple), alors elle doit être automatisée.
Le « toil » (labeur) est un travail manuel, répétitif ou automatisable qui n’apporte pas de valeur à long terme. Le SRE a pour but d’identifier et de réduire le toil afin de permettre aux ingénieurs de se concentrer sur des tâches à plus forte valeur ajoutée.
Lorsqu’un incident survient, les équipes SRE mènent une analyse post-mortem pour en comprendre la cause profonde et mettre en place des actions préventives.
Enfin, le SRE promeut une culture où les équipes assument la responsabilité collective de la fiabilité tout en encourageant l’innovation et la prise de risques calculés.
Le Site Reliability Engineer révolutionne la gestion des infrastructures en combinant les principes du développement logiciel et des opérations. C’est un peu l’administrateur système boosté aux stéroïdes. Cette approche permet de créer des systèmes hautement fiables et scalables tout en optimisant les processus clés comme les alertes, le provisioning et les opérations quotidiennes. En intégrant les pratiques GitOps, les équipes SRE peuvent bénéficier d’une gestion encore plus efficace et transparente.
Le saviez-vous ?
Une nuit chez Google, un ingénieur SRE a été réveillé par une alerte critique signalant une panne d’un service clé. Rapidement, l’équipe s’est mobilisée pour diagnostiquer le problème en temps réel. Grâce à des scripts automatisés, un correctif a été déployé en moins d’une heure. L’analyse post-mortem qui a suivi a permis d’améliorer les tests automatisés, prévenant ainsi de futures régressions. Cet incident a démontré l’efficacité des pratiques SRE et renforcé la fiabilité des services de Google.
La gestion du toil : améliorer la productivité
La SRE (Site Reliability Engineering) ne se limite pas à la simple administration de systèmes. Elle se concentre en grande partie sur la réduction du toil (labeur en anglais). Le toil représente des tâches répétitives, manuelles et sans valeur ajoutée qui consomment du temps et des ressources précieuses à l’entreprise.
Ces tâches, déclenchées par des événements plutôt que par des choix créatifs, n’ajoutent pas de valeur durable au travail des ingénieurs. Elles empêchent les équipes de se concentrer sur des activités plus stratégiques et innovantes.
Le toil peut avoir plusieurs impacts négatifs sur les équipes. Il peut entraîner :
- Une démotivation et un épuisement professionnel à cause de la répétition incessante de tâches monotones.
- Une perte de productivité puisque le temps consacré au toil n’est pas investi dans l’amélioration de la performance des systèmes.
- Des opportunités manquées car les équipes disposent de moins de temps pour innover et améliorer les processus existants.
Pour réduire le toil, l’automatisation est la clé. En automatisant les tâches répétitives, les équipes disposent de plus de temps pour se consacrer à des activités à plus haute valeur ajoutée. Enfin, il est important de former les équipes à reconnaître le toil et à utiliser des pratiques et des outils qui minimisent son impact.
Voici quelques exemples concrets d’application :
- La gestion de l’infrastructure via du code, grâce à l’Infrastructure as Code (IaC), permet une mise en place et une gestion automatisée et reproductible des environnements.
- L’automatisation des déploiements grâce à des pipelines CI/CD réduit les interventions manuelles et les erreurs humaines.
- Le déploiement de systèmes de surveillance proactive détecte et corrige automatiquement les anomalies avant qu’elles n’affectent les utilisateurs.
- L’adoption d’outils modernes de gestion des incidents, de surveillance et d’alertes (observabilité) permet aussi de réduire le besoin d’intervention manuelle.
Réduire le toil est donc essentiel pour les équipes SRE (Site Reliability Engineering). Cela améliore non seulement leur efficacité et leur satisfaction au travail, mais aussi la robustesse et la scalabilité de l’infrastructure. En se concentrant sur l’automatisation et l’optimisation des processus, les équipes SRE peuvent transformer des tâches répétitives en opportunités d’innovation et de croissance.
L’observabilité
L’observabilité est un élément clé dans la pratique du Site Reliability Engineering et s’inscrit parfaitement dans la philosophie DevOps. Elle permet aux ingénieurs de surveiller, diagnostiquer et optimiser les systèmes complexes, assurant ainsi leur fiabilité et leur performance. Dans un environnement DevOps, l’observabilité est essentielle pour comprendre l’état des systèmes en production et pour prendre des décisions éclairées basées sur des données en temps réel.
L’observabilité représente la supervision moderne et avancée des systèmes, surpassant largement les outils traditionnels tels que Nagios. Alors que Nagios et ses équivalents se contentent de fournir des alertes basiques et une surveillance des états, l’observabilité permet une compréhension approfondie et instantanée des performances et de la santé des systèmes. Cette approche est essentielle pour les pratiques du Site Reliability Engineering.
Les 3 piliers de l’observabilité :
1. Logs
Description : Les logs sont des enregistrements détaillés des événements qui se produisent dans un système. Ils fournissent un historique complet des opérations et des erreurs.
Utilisation : Les logs sont utilisés pour retracer les événements après un incident, analyser les comportements anormaux et comprendre l’historique des transactions système.
2. Metrics
Description : Les métriques sont des mesures quantitatives des performances du système. Elles incluent des données comme l’utilisation du CPU, la mémoire, les taux de requêtes, et les temps de réponse.
Utilisation : Les métriques permettent de surveiller en temps réel l’état du système, d’identifier les tendances, et de déclencher des alertes en cas de dépassement de seuils critiques (cf. capture d’écran ci-après représentant un dashboard de logs dans une instance Grafana, de Néosoft).
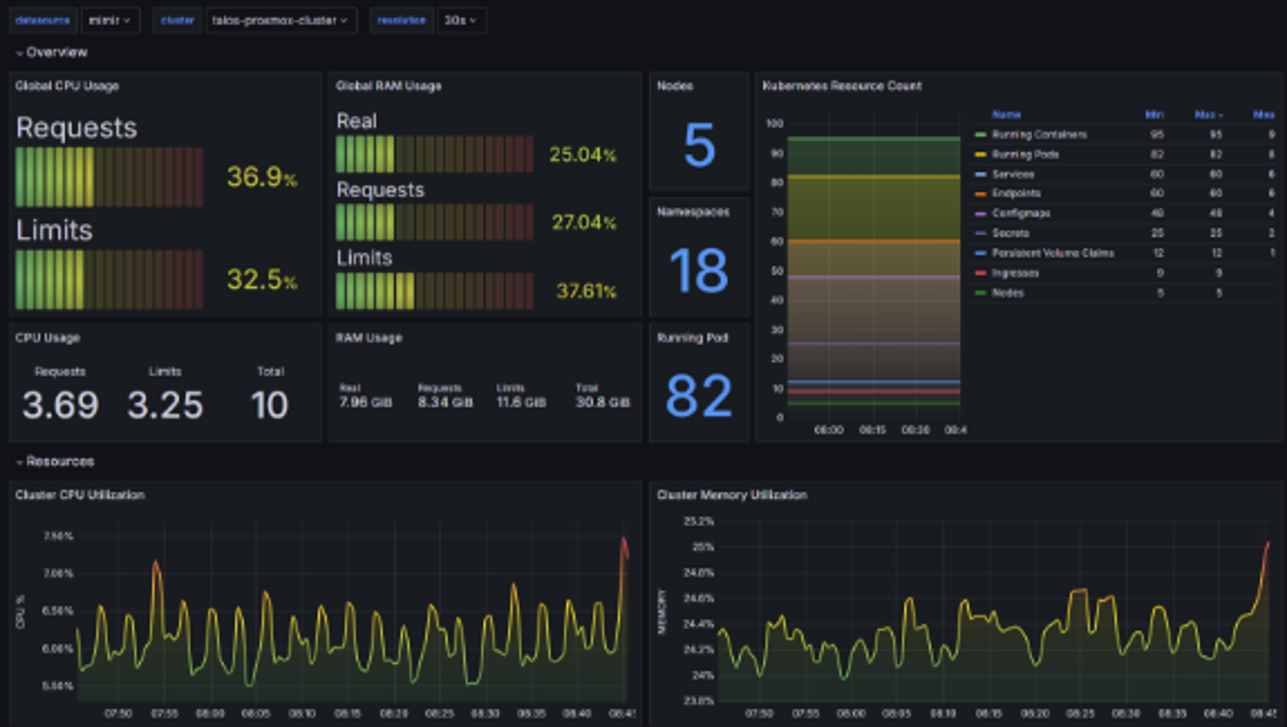
3. Traces
Description : Les traces retracent le chemin des requêtes à travers les différentes composantes d’un système distribué. Elles révèlent comment les requêtes sont traitées et où elles passent du temps.
Utilisation : En identifiant les goulots d’étranglement, les traces sont cruciales pour diagnostiquer les problèmes de latence et de performance dans les architectures de microservices.
L’observabilité est essentielle en Site Reliability Engineering, elle permet de surveiller en temps réel la santé des systèmes, d’identifier rapidement les problèmes et de les résoudre avant qu’ils n’affectent les utilisateurs. Au-delà du SRE, une bonne observabilité améliore la compréhension des comportements des systèmes complexes, facilitant l’optimisation des performances et la prise de décisions éclairées.
Pour mettre en œuvre l’observabilité dans la pratique du SRE, il est essentiel de :
- Collecter des données de manière uniforme et centralisée.
- Analyser ces données afin de diagnostiquer les problèmes, optimiser les performances et planifier les capacités. Utiliser des solutions d’intelligence artificielle et de machine learning peut faciliter la détection des anomalies et la prédiction des pannes avant qu’elles ne surviennent.
- Configurer des tableaux de bord interactifs et des alertes afin de surveiller les systèmes de manière proactive. Grafana est un excellent outil pour la visualisation et la gestion centralisée des métriques, logs, ou traces. Des outils comme Prometheus pour la collecte de métriques, ELK Stack (Elasticsearch, Logstash, Kibana) pour les logs, et Jaeger ou Zipkin sont également particulièrement efficaces.
- Automatiser les réponses aux incidents. Implémenter des scripts et des workflows automatisés permet de répondre aux incidents sans intervention humaine, réduisant ainsi le toil. Des plateformes d’orchestration comme Kubernetes peuvent être utilisées pour automatiser ces réponses, assurant une réactivité optimale et une haute fiabilité.
L’observabilité permet de transformer des données brutes en insights actionnables, aidant les équipes SRE à maintenir la fiabilité et la performance des systèmes. En fournissant une visibilité complète sur l’état des systèmes, elle permet de détecter et de résoudre les problèmes rapidement, minimisant ainsi les interruptions de service et améliorant l’expérience utilisateur.
Le saviez-vous ?
Un ingénieur SRE de Netflix a expliqué comment l’observabilité leur a permis de détecter et résoudre rapidement un problème de latence affectant certains utilisateurs. Les traces ont révélé que le problème provenait d’un microservice sous forte charge. En ajustant sa configuration et en ajoutant des ressources, ils ont pu résoudre le problème efficacement. Cette intervention rapide a également réduit le toil, permettant aux ingénieurs de se concentrer sur des tâches à plus forte valeur ajoutée, telles que l’optimisation des performances et l’amélioration de la résilience du système. Cet exemple illustre comment l’observabilité et la gestion du toil se complètent pour renforcer la fiabilité et l’efficacité des opérations.
Mesures, indicateurs et objectifs SRE
Pour garantir la fiabilité et la performance des systèmes, les équipes SRE suivent une série d’indicateurs clés et établissent des objectifs clairs. Ces indicateurs, souvent définis par des accords de niveau de service (SLA) et des objectifs de niveau de service (SLO), permettent de mesurer et de maintenir la qualité des services fournis. Le tableau ci-dessous résume les principaux indicateurs et objectifs pour le SRE :
| Indicateur | Définition | Objectif (SLO) |
|---|---|---|
| Budget d’erreur (Error Budget) | Quantité maximale d’erreurs acceptables sur une période donnée avant que des mesures correctives ne soient prises. | Ne pas dépasser le budget d’erreur défini |
| Disponibilité (Uptime) | Pourcentage du temps pendant lequel le service est disponible et opérationnel. | Assurer une disponibilité de 99.99% |
| Taux d’erreur (Error Rate) | Pourcentage des requêtes qui échouent. | Maintenir un taux d’erreur inférieur à 0.01% |
| MTTR (Mean Time to Repair) | Temps moyen nécessaire pour réparer un système ou service après une panne. | Réduire le MTTR à moins de 30 minutes |
| MTBF (Mean Time Between FaiIures) | Temps moyen entre deux pannes successives. | Augmenter le MTBF à plus de 1 an |
| Taux de succès des déploiements (Deployment Success Rate) | Pourcentage des déploiements qui se déroulent sans incident. | Atteindre un taux de succès de déploiement de 95% ou plus |
En parallèle de ces indicateurs de performance, et comme vu précédemment, la gestion du toil est cruciale pour les équipes SRE.
SRE et DevOps : une synergie parfaite
DevOps et les pratiques du Site Reliability Engineering (SRE) ne sont pas des concepts opposés, mais plutôt des méthodologies complémentaires qui, ensemble, créent une synergie puissante.
Le DevOps est avant tout une philosophie qui vise à briser les silos entre les équipes de développement et des opérations. En favorisant la collaboration et l’automatisation des processus, DevOps permet de livrer des logiciels plus rapidement et de manière plus fiable. Les principaux concepts du DevOps incluent l’intégration continue (CI), le déploiement continu (CD) et l’infrastructure as code (IaC). Ces pratiques améliorent la vitesse de développement et la qualité des livraisons tout en réduisant les risques de défaillances grâce à des déploiements incrémentiels et fréquents.
Le Site Reliability Engineering est une discipline qui applique les principes de l’ingénierie logicielle à la gestion des opérations pour créer des systèmes scalables et fiables. Les SRE se concentrent sur l’automatisation, la gestion des incidents et l’observabilité pour garantir la disponibilité, la performance et la résilience des services. Les pratiques SRE incluent la définition et la gestion des objectifs de niveau de service (SLO), l’utilisation de budgets d’erreur pour équilibrer l’innovation et la stabilité, ainsi que la réduction dutoilpar l’automatisation.
La combinaison de DevOps et de SRE offre une approche holistique de la gestion du cycle de vie des logiciels, de la conception à la production. L’automatisation des builds, des tests et des déploiements par DevOps, ainsi que l’automatisation de la surveillance, des alertes et des réponses aux incidents par SRE, réduisent le toil et libèrent les ingénieurs pour se concentrer sur des tâches à forte valeur ajoutée.
En utilisant des outils de CI/CD pour des déploiements fréquents et sans interruption, DevOps et SRE garantissent une livraison rapide et fiable des fonctionnalités, tout en maintenant une haute performance et résilience des systèmes grâce à l’observabilité. DevOps encourage l’amélioration continue à travers des itérations rapides, tandis que SRE gère les incidents avec des processus structurés, apprenant de chaque incident pour éviter les futures occurrences. Leur approche combinée assure une amélioration continue et une réactivité optimale face aux incidents.
Conclusion
DevOps et SRE, lorsqu’ils sont intégrés de manière cohérente, créent une boucle vertueuse où la rapidité, la qualité et la fiabilité se renforcent mutuellement. Il est donc primordial de comprendre comment elles se complètent pour offrir des services robustes, scalables et hautement performants. Ensemble, DevOps et SRE transforment la manière dont les organisations développent, déploient et maintiennent leurs applications, assurant une valeur continue pour les utilisateurs finaux et une efficacité opérationnelle pour les équipes. En unissant leurs forces, DevOps et SRE permettent aux entreprises de répondre aux exigences croissantes du marché tout en maintenant des standards élevés de qualité et de fiabilité. C’est cette synergie qui fait de leur combinaison une stratégie gagnante pour toute organisation cherchant à exceller dans le paysage technologique moderne.