
IA & IA générative – Risques et recommandations de sécurité

Sommaire
- De nouveaux risques
- Pourquoi cet article ?
- Les risques dans les différentes phases du projet
- Les sources de risques et/ou de menaces
- Nos recommandations
De nouveaux risques
Depuis 2022 bon nombre d’outils utilisant l’intelligence artificielle sont rendus accessibles et l’offre ne cesse de croitre en qualité, mais surtout en quantité. Ses projets vont très certainement continuer à voir le jour et, peut-être, avez-vous, vous même des idées « powered by AI » derrière la tête. Cependant, on peut rapidement oublier que cet outil expose à de nouveaux risques en plus de ceux communs à tous les projets informatiques.
Définition rapide de l’IA et d’un projet IA
Le terme d’IA englobe beaucoup de concepts et de définitions et, par soucis de compréhension, il nous faut le définir dans le contexte de cet article. On parle ici de modèles mathématiques avancés, d’algorithmes et de leurs différents paramètres. Nous allons principalement parler de la sous-catégorie des IA génératives, qui permettent de générer du contenu en réponse à une requête en langage naturel (un prompt) à partir d’un modèle entrainé sur une batterie plus ou moins importante de données.
L’IA ne doit pas être considérée comme la solution universelle à tous les problèmes et toutes les tâches n’ont pas intérêt à être assurée ou assistée par l’IA. Une IA reste un réseau de neurones ou un autre modèle mathématique entrainé pour des tâches complexes mais précises. Les projets IA sont particuliers tant dans l’infrastructure qu’ils nécessitent que dans le nombre de composants externes en interaction avec lui.
Pourquoi cet article ?
Les règlementations concernant l’IA commencent à voir le jour et à être appliquées (Ai-act, Executive Order 14110), le corpus documentaire et les Frameworks sont de plus en plus nombreux et la technologie IA progresse rapidement. En proposant un aperçu de la surface d’attaque, des menaces et des risques qui pèsent sur l’IA, cet article permet de prendre conscience de la sensibilité de ces projets et il met en avant des points d’attentions à ne pas négliger lors de la conduite d’un projet IA.
Pour qui ?
Cet article est accessible à tous et contient des informations pertinentes pour tout type de population (population non initiée, développeurs, chefs de projet, exploitants, auditeurs…). La liste des risques, vulnérabilités potentielles, menaces, et impacts n’est pas exhaustive et chaque section de cet article pourrait faire l’objet d’un guide ou d’un article dédié tant le sujet est vaste.
Les risques dans les différentes phases du projet
Avant toute chose, il vous faudra choisir un modèle : c’est-à-dire, comme défini plus haut, la construction mathématique la plus adéquate et la plus pertinente au regard des données à traiter et du type de réponse attendu. Cela peut par exemple se faire en mettant en compétition différents modèles sur les données d’entrainement afin d’identifier la combinaison du modèle et des paramètres la plus performante.
La conception
Il faut aussi garder à l’esprit que tous les modèles ne garantissent pas les mêmes niveaux de sécurité ni les mêmes fonctionnalités : protection contre l’extraction de modèle, chiffrement des opérations et des données, protection contre le probing (tenter d’extraire des informations permettant de comprendre les mécanismes internes au modèle), implémentation de la confidentialité différentielle….
Un projet IA devient, ensuite, rapidement complexe, avec des sous-composants qui vont interagir de manière très étroite les uns avec les autres. La surface d’attaque va, en partie, dépendre des bibliothèques, des modules, de l’infrastructure et des jeux de données utilisés par le modèle. La compromission d’un seul de ces composants permet une latéralisation rapide et facile du fait de leur imbrication.
Réaliser et maintenir une cartographie dynamique de ces actifs est donc particulièrement important et complexe dans les projets IA : ils sont amenés à évoluer continuellement et plus régulièrement que les autres projets informatiques. Le modèle doit être régulièrement ré-entrainé avec de nouvelles données et la forte dépendance à l’environnement matériel (GPU, serveurs spécialisé…) et son évolution fréquente peuvent rapidement introduire de nouvelles vulnérabilités si elles ne sont pas maitrisées. Ces évolutions rapides nécessitent donc une vigilance accrue pour assurer la sécurité et la maîtrise des actifs tout au long du cycle de vie du projet.
Ce fort besoin de composants, souvent dédiés à ce genre de projet, renforce la nécessité d’établir une relation de confiance avec les fournisseurs et de la contractualiser, que ce soit au niveau des bibliothèques utilisées (cas de PyTorch en 2022), des composants matériels (Supermicro en 2018), des environnements de virtualisation (Compromission de DockerHub en 2019) ou même des données d’entrée et des modèles utilisés (PoisonGPT).
Le choix de format des fichiers accueillant les paramètres du modèle utilisé est aussi un point à prendre en compte : certains formats comme pickle ou pdparams sont réputés comme vulnérables à l’exécution de code illégitime et sont donc à proscrire.
Le développement et l’entrainement
Les données d’entrainement représentent une surface d’attaque inédite et est une des cibles favorites des acteurs malveillants ciblant les systèmes d’IA .Un jeu de données pollué (volontairement ou non) peut provoquer des incidents plus insidieux que dans les projets classiques : prise de décisions dangereuses par le système, résultats biaisés, exfiltration de données… Ces incidents peuvent avoir des impacts plus ou moins importants en fonction du contexte du projet (mauvaise prise de décision dans un système d’imagerie médical, désinformation…).
S’assurer de la qualité des données d’entraînement consiste à s’assurer qu’elles ne contiennent pas de données personnelles, qu’elles respectent les différentes lois et règlementations (AI Act, Copyrights, RGPD…), qu’elles ne contiennent pas d’informations dangereuses ou encore qu’elles ne contiennent pas de biais majeurs non souhaités. La composition, les sources et les changements apportés sur les jeux de données d’entraînement doivent être tracés afin de pouvoir repérer plus efficacement les cas de pollution de données.
Pour ce faire, plusieurs mécanismes peuvent être implémentés pendant le développement :
- Application de méthode de filtrage des données (KPPV, détection des nouveauté
- SVM…) couplées à des corrections manuelles ;
- Implémentation de méthodes de calculs utilisant le chiffrement homomorphique (les données d’entrainement sont chiffrées et n’ont pas besoin d’être déchiffrées pour être exploitées par le système) ;
- Utilisation de Frameworks sécurisés pour l’entrainement comme TensorFlow Privacy de Google ;
- Ajuster les politiques internes afin de respecter les Frameworks de développement sécurisé dédié à l’IA (NIST SP-800-218A, NIST.AI.600-1).
Cependant, toutes ces mesures seront inefficaces si les bonnes pratiques de développement sécurisé ne sont pas appliquées. Une approche DevSecOps est à privilégier afin d’assurer l’harmonisation des différents acteurs du projet tout en améliorant la sécurité des processus.
Le déploiement
C’est à partir d’ici que l’IA est la plus vulnérable, les vecteurs d’attaque se multiplient du fait des nombreux échanges avec les différents composants d’infrastructure nécessaires et l’entrée en jeu de l’utilisateur dans l’équation. Avant le déploiement, la réalisation d’audits de sécurité, est vivement recommandée (cf.R23 du guide de l’ANSSI dédié aux systèmes d’IA). Assurez-vous également de garder une version de référence du modèle qui permettra un retour en arrière rapide en cas d’empoisonnement des entrées utilisateurs.
Le principale risque auquel s’expose le projet une fois déployé sont les attaques « adversariales ». Assez semblables aux injections, elles consistent à tirer parti du fonctionnement statistique des IA en manipulant subtilement les données d’entrées (différentes des données d’entrainement, prompts par exemple) afin de produire des résultats erronés ou des comportements indésirables : altération de quelques pixels soumis à un système d’imagerie, utilisation de fréquence inaudible sur un assistant vocal, tournure de phrase particulière…
Se prémunir de ce type d’attaque se fait à différents niveaux et plusieurs solutions peuvent être associées afin d’améliorer la robustesse du modèle :
- Distillation défensive : le modèle est formé à imiter les prédictions d’un autre modèle plus grand ;
- Lissage des résultats : rendre le modèle moins sensible aux petites variations via différentes techniques (régularisation de Tikhonov, noyaux de lissage…) ;
- Prétraitement des données : Eliminer les perturbations adversariales via des transformations inconnues de l’utilisateur ;
- Entraînement adversarial : inclusion d’exemples adversariaux dans les données d’entrainement pour habituer le modèle à reconnaitre ce genre de perturbation.

Le déploiement expose également un peu plus l’infrastructure qui n’embarquera pas les même mesures qu’une infrastructure classique. Il convient de mettre en place un cloisonnement à plusieurs niveaux, par exemple :
- Les différents environnements du cycle de vie (entrainement, déploiement…) ne doivent pas être inters communicants ;
- Les cartes graphiques (ou GPU) doivent être dédiées au projet ;
- Les environnements du système d’IA doivent être séparé des environnements des autres projets (séparation physique et logique).
Ces précautions permettent de limiter les capacités de latéralisation en cas de compromission d’un des composants du système ou de l’infrastructure en général. Elles permettent également de faire en sorte que les besoins métier soient satisfaits en cas de compromission du système d’IA. Cela permet surtout de ne pas imposer le même rythme d’évolution aux parties du SI qui ne seraient pas impliquées dans votre projet IA et donc d’en garder plus facilement le contrôle.
La maintenance
La nature d’un système d’IA induit une évolution permanente. En plus de la cartographie mentionnée plus haut, une surveillance et une traçabilité des requêtes utilisateurs et des réponses du modèle est nécessaire, afin de prévenir toute dérive du modèle ou de créer des nouvelle règles/filtres permettant d’améliorer la sécurité de ce dernier.
Une documentation complète des différents jeux de données doit également être maintenue dans le même but. Cette documentation doit contenir les sources, indiquer le format des données, établir une fréquence de mise à jour qui doit être scrupuleusement respectée, préciser les règles d’accès (qui devront être appliquées) et expliquer ou référencer toutes les étapes permettant de s’assurer de la qualité des données : méthode de préparation, biais connus, procédure en cas de détection de données invalides…
Le modèle représente aussi une nouvelle source de vulnérabilité, ou plus précisément ses algorithmes, et il devra donc être régulièrement mis à jour au même titre que les bibliothèques et l’infrastructure. Les différentes recommandations citées plus haut doivent également persister à chaque itération du cycle de vie du système qui doit faire l’objet d’opérations de maintenance bien plus régulières qu’un autre projet informatique.
Les sources de risques et/ou de menaces
L’humain
Dans un projet IA s’assurer de la confiance et de l’alignement des idées dans l’équipe projet est primordiale afin d’obtenir les comportements attendus par le système. L’aspect éthique de tels projets peut être un point dur pour certaines équipes et, si le projet est lancé sans concertation, les opérations de sabotage deviennent vraisemblables. L’AI act est, en plus d’une obligation légale, un bon outil permettant d’évaluer les problématiques éthiques que peuvent soulever le projet.
En plus de la confiance, la maîtrise de la technologie IA doit être assurée. Si les équipes ne sont pas formées ou spécialisées dans l’IA, les risques projets ne seront pas contrôlables.
Il est donc important que les équipes soient formées sur les particularités inhérente à un projet IA et ses mécanismes.
Les utilisateurs et acteurs malveillants ne peuvent être maitrisés mais, comme vu précédemment, en appliquant les bonnes méthodes et les bons mécanismes il est possible de réduire la vraisemblance d’un incident. Les référentiels de sécurité du NIST (NIST SP800-218A, NIST.AI.600-1) présentent un ensemble de mesures à mettre en place en ce sens.
D’après le référentiel des risques de l’IA du MIT, l’humain est susceptible d’être la cause de 34% des incidents référencés, ce qui est moins que dans le commun des projets informatiques n’embarquant pas d’IA, ce qui signifie que la majorité des points de contrôle concerne…
L’IA
La majorité des incidents proviennent de l’IA en elle-même : problème de conception, mauvaise configuration, modèle trop ancien… tant d’aspects qui, malgré une utilisation légitime du système, peuvent provoquer un incident.
Toujours d’après le MIT, ce sont cette fois-ci 51% des incidents qui sont provoqués par l’IA, victime d’une mauvaise conception ou d’un mauvais encadrement du projet. Cela montre l’importance des études à réaliser avant le lancement du projet, de la prise en compte des différentes règlementations ainsi que, encore une fois, l’importance de mobiliser du personnel compétent sur le projet.
Lorsque le système d’IA est la source du problème, l’impact ne se produit pas sur le système mais plutôt dans ses méthodes de calcul et ses réponses. La gravité des incidents dépendra donc du contexte dans lequel l’IA est utilisée. L’impact peut également devenir juridique en cas de fuite de données sensibles par exemple.
L’environnement du projet
Le langage de programmation et les outils utilisés dans la chaine de développement, l’infrastructure d’hébergement, les frameworks… Tous ces éléments peuvent provoquer des incidents ou, à minima, servir de vecteur d’attaque. L’environnement représente 15% des risques directs mais ils représentent, dans le même temps, la majorité des outils permettant la compromission du système d’IA.
En plus des risques déjà mentionnés plus haut, il faut prendre en compte que l’infrastructure du projet est fortement sollicitée et des tests de charge doivent être menés afin de s’assurer de sa résilience.
Les impacts
D’après la littérature scientifique, les incidents relatifs à un système d’IA peuvent avoir des impacts variés : désinformation, impact éthique, impact écologique, impact socioéconomique… Il est important de réaliser qu’un incident sur un système IA peut autant impacter votre équipe projet que les utilisateurs.
Votre IA, si compromise, peut également servir de vecteur de distribution de charge malveillante, et votre image en serait rapidement ternie.
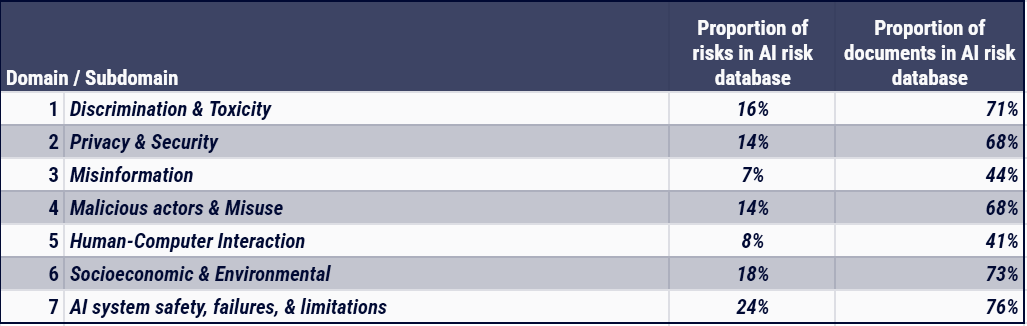
Extrait de la Risk Database du MIT, représentant la répartition des types d’impacts des incidents documentés
Nos recommandations
La sécurisation d’une IA est donc particulièrement complexe, afin de vous aider, il est fortement recommandé de faire appel à des spécialistes (internes ou externes) afin de réaliser différents types d’audit et d’analyses (analyse de risque, test d’intrusion, audit d’infrastructure a minima)
Côté projet certaines précaution peuvent tout de même être prises :
- Prendre le temps de concevoir le projet : son périmètre d’action, ses fonctionnalités
- Définir les responsabilités ;
- Bien choisir ses outils et surtout le langage de programmation ;
- S’assurer de la confiance envers les équipes et les fournisseurs ;
- Surveiller et restreindre le contenu des jeux de données d’entrainement ;
- Proscrire l’IA pour les activités sensibles car les accès aux données d’entrée ne peuvent pas être gérés ;
- Accorder les politiques internes aux enjeux de l’IA ;
- Implémenter des mécanismes réduisant la probabilité de réussite d’une attaque adversariale.
Bibliographie
- Secure Software Development Practices for Generative AI and Dual-Use Foundation Models: An SSDF Community Profile.
NIST SP 800-218A, NIST, juillet 2024
https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-218A.pdf - Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile.
Site institutionnel, NIST, juillet 2024
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf - The AI Risk Repository: A Comprehensive Meta-Review, Database, and Taxonomy of Risks From Artificial Intelligence
Etude, MIT, 13 août 2024
https://cdn.prod.website-files.com/669550d38372f33552d2516e/66bc918b580467717e194940_The%20AI%20Risk%20Repository_13_8_2024.pdf - Artificial Intelligence Act.
Site institutionnel, Parlement européen, 13 mars 2024
https://www.europarl.europa.eu/doceo/document/TA-9-2024-0138_EN.html - Recommandations de sécurité pour un système d’IA générative
Guide ANSSI-PA-102, ANSSI, 29 avril 2024
https://cyber.gouv.fr/sites/default/files/document/Recommandations_de_s%C3%A9curit%C3%A9_pour_un_syst%C3%A8me_d_IA_g%C3%A9n%C3%A9rative.pdf - An Explanation of the Guidelines for Secure AI System Development.
Article, CSA, 28 février 2024
https://cloudsecurityalliance.org/blog/2024/02/28/an-explanation-of-the-guidelines-for-secure-ai-system-development - A sensible regulatory framework for AI security
Site institutionnel, MITRE, juin 2023
https://www.mitre.org/sites/default/files/2023-06/PR-23-1943-A-Sensible-Regulatory-Framework-For-AI-Security_0.pdf