
Retour sur Inforsid 2025

Sommaire
- Gouvernance des données : vers un cadre conceptuel
- Restriction d’accès à l’information scientifique : impact sur les LLM
- Le Forum « Jeunes Chercheuses, Jeunes Chercheurs »
- Et encore bien d’autres sujets à explorer…
- Ressources
Inforsid 2025
Du 3 au 6 juin 2025 s’est tenu le 43e congrès Inforsid, au sein de l’Université de Pau et des Pays de l’Adour. Cet évènement est l’occasion de présenter travaux de recherche, développements industriels et expériences significatives dans le domaine de l’ingénierie et des systèmes d’information. Sont attendus également des travaux plus exploratoires ou des idées à débat.
Cette année le thème était « Éthique, Équité et Systèmes d’Information : construire un numérique responsable et inclusif ». Il y est alors question de dépasser l’objectif de recherche permanente de la performance pour tendre vers des notions de responsabilité, inclusivité, respect de l’éthique et d’équité. Cette vision, partagée également pas la conférence Green Days de 2025, démontre la prise de conscience des ingénieurs, enseignants, et chercheurs, de leur rôle à jouer dans cette trajectoire.
Deux keynotes ont marqué l’événement : Sergio Ilarri sur la gestion des données et la société durable, et Olivia Tambou sur le cadre juridique et éthique de l’IA en Europe. Trois ateliers ont permis d’aborder concrètement des questions d’éco-responsabilité, responsabilité sociale et gouvernance numérique. Le FJCJC, avec 18 participants dont moi, a présenté des travaux variés, notamment une conciliation entre sécurité et environnement, gestion des carrières, ou qualité de vie en Corse.
Je vous propose de vous présenter deux papiers de conférences auxquelles j’ai assisté, portant sur les données, leur gouvernance et leur accessibilité.
Gouvernance des données : vers un cadre conceptuel
Conférence de : Isabelle COMYN-WATTIAU
Contexte et objectifs de l’étude
Les données sont au centre de nos organisation et la gouvernance est la discipline permettant de cadrer et responsabiliser les acteurs de la gestion des données. Malgré une exploration académique depuis 2005, qui a connu un intérêt croissant, un manque de consensus persiste sur la définition même de cette notion. Le papier présenté vise à identifier les thématiques de recherche majeures et à structurer les différents éléments clés de la gouvernance des données.
Pour cette étude, Jacky Akoka et Isabelle Comyn-Wattiau ont utilisé la bibliométrie. Selon le site de la bibliothèque universitaire de La Rochelle, la bibliométrie est « l’application de méthodes statistiques et mathématiques pour mesurer et évaluer la production et la diffusion de publications ». Cette approche permet de repérer des cluster d’articles cités (analyse des co-citations), des ensembles d’articles partageant des références communes (analyse des couplages bibliographiques), ou encore les travaux les plus influents (analyse des chemins principaux). Les articles en anglais contenant le terme « data governance » dans leur titre, résumé ou mots-clés ont été extraits de la base Scopus, puis triés manuellement pour sélectionner un échantillon de 2700 publications.
Évolution historique et analyse bibliométrique
L’analyse descriptive du corpus révèle une évolution depuis 2005, date de la première apparition du terme « gouvernance des données ». Les auteurs présente cette évolution en trois phases : embryonnaire, exploratoire, puis amplification, qui a démarré en 2018. Entre 2018 et 2024, le nombre de publications a bondi de 109 à 626, soit une hausse de plus de 500 %. Parmi les auteurs, Rob Brennan se distingue avec 20 publications, ce qui en fait le seul auteur dépassant les 15 publications sur le sujet. Une caractéristique majeure de la gouvernance des données est sa multidisciplinarité, avec des contributions issues de l’informatique, des sciences sociales, de la médecine ou des mathématiques.
L’analyse des co-citations, sur un sous-ensemble d’articles cités plus de 30 fois, a identifié trois groupes d’articles : un premier axé sur la dimension organisationnelle avec des modèles et cadres conceptuels, un second qui élargit cette perspective, et un troisième axé sur des revues de littérature récentes. L’analyse des couplages bibliographiques a révélé six clusters supplémentaires, répartis en deux catégories : les travaux fondateurs de la gouvernance des données, et ceux explorant son application dans d’autres domaines. Le chemin principal, c’est-à-dire le chemin avec les arcs les plus fréquenté dans le graphe, débute par l’article de Khatri et Brown de 2010, « Designing data governance » (lien). Celui ci définit la gouvernance des données en 5 dimensions – Les principes des données, la qualité des données, les métadonnées, l’accès aux données, le cycle de vie des données – et la distingue de la gestion des données, perçue comme son opérationnalisation. Il inclue également l’article de Abraham et al. de 2019, « Data governance: A conceptual framework, structured review, and research agenda » qui propose un cadre selon 3 dimensions : types de données, niveau organisationnel, processus de mise œuvre.
Cadre conceptuel : proposition et application
Akoka et Comyn-Wattiau proposent ensuite un cadre conceptuel basé sur la théorie des systèmes, composé de cinq éléments : le but, la structure, les activités, l’environnement et les résultats. Ces dimensions sont en relation entre elles car agir sur l’une va avoir une incidence sur les autres.
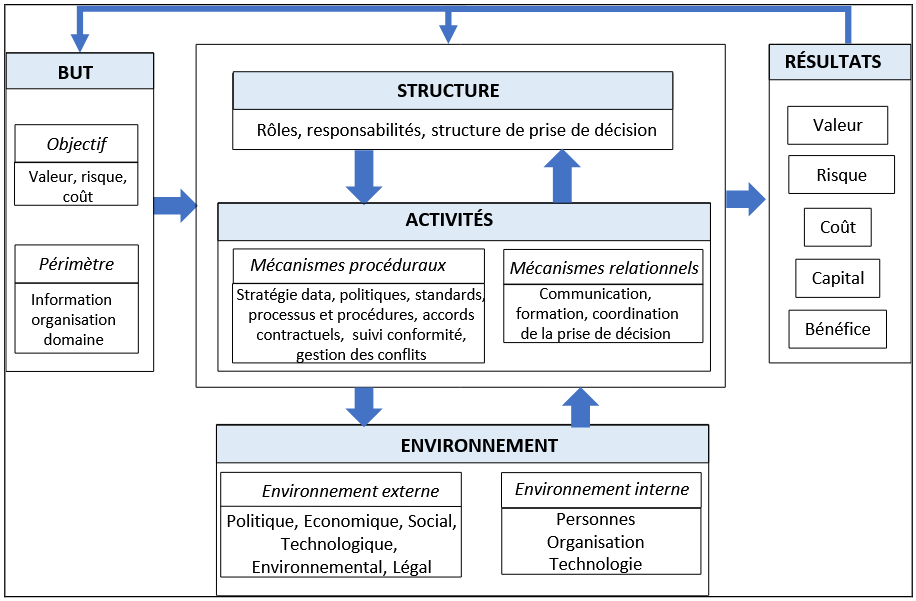
L’avis de l’expert
Les techniques bibliométriques présentées sont très intéressantes puisqu’elles offrent une vision synthétique et pertinente d’un domaine. Appliquée à la gouvernance des données, elles ont permis de la structurer, malgré une explosion de l’intérêt depuis 2018. On comprend assez vite que bien que, depuis 2018, le sujet suscite de plus en plus d’intérêt, il reste encore a structurer. Des recherches sont encore à mener pour clarifier cette discipline en pleine émergence. La gouvernance des données est un sujet passionnant qui permet d’apporter de vraies réponses quant à la performance d’une organisation.
Restriction d’accès à l’information scientifique : impact sur les LLM
Entre qualité et accès aux données
Il n’y a pas de données sans usage. Et parmi le champ des possibles, la création des Intelligence Artificielle Générative (IAG) s’est avérée être un usage particulièrement intéressant, voir stratégique pour les organisations. Chez Néosoft, nous avons choisi une démarche open source pour la création de notre IAG interne NéoGen, qui repose sur des modèles ouverts. Bien souvent, la qualité des réponses générées par un IAG est souvent liée à la qualité des jeux de données utilisés pour la fabrication. C’est pourquoi, comme pour le contenu journalistique, il est crucial de comprendre l’origine des publications scientifiques intégrées dans leur entraînement.
L’accès à ces contenus est souvent verrouillé par les éditeur, comme Elsevier, Springer Nature, qui contrôlent les publications. Par exemple, John Wiley & Sons, l’éditeur d’une publication de Ali Ghaderi et Zeinab Movahedi traitant de gestion des données (lien), propose plusieurs niveau d’accès allant de l’accès pendant 48h, en ligne pour 12$, au téléchargement en pdf avec accès en ligne pour 49$. Cette pratique des éditeurs encourage l’apparition de revues dites prédatrices, qui privilégient un processus de contrôle léger ou inexistant, tout en proposant des tarifs bas. Ce système est néfaste car favorise la diffusion de publications de mauvaise qualité en accès libre.
La collecte de données pour ces IAG est souvent automatisée. L’objectif de cette collecte est la récupération de pages web contenant de l’information scientifique. Des méthodes de blocages existent pour l’empêcher. Parmi les blocages possibles, l’utilisation d’un fichier appelé robot.txt permet de stopper les robots de scraping d’accéder à des pages. Robert Viseur nous propose d’étudier la question de l’impact de cette restriction sur la qualité des modèles que nous utilisons tous les jours.
Les robots d’IAG face aux éditeurs scientifiques
Pour questionner l’impact de ces restrictions sur les robots d’IAG , Robert Viseur étudie un corpus de revues divisé en deux catégories : les revues prédatrices et celles de bonne qualité. Il a examiné les fichiers robot.txt de ces sites, identifié les robots d’exploration les plus fréquents, et calculé le pourcentage de blocage par robot. Les robots d’exploration des moteurs de recherche (comme celui de Google) sont distingués de ceux utilisés par les acteurs de l’IAG.
Les résultats révèlent une tendance : les robots d’IAG rencontrent un blocage plus intense sur les sites de revues, surtout lorsque ces dernières sont de haute qualité. Les revues du top 50 montrent un taux de blocage élevé, tandis que les revues prédatrices y restent indifférentes. Parmi les robots d’IAG, GPTbot suscite le plus d’inquiétude chez les revues de bonnes qualités. Le tableau suivant illustre ces taux de blocage en fonction du niveau de qualité des revues (de 0 à 2) et du top 50. Il compare les robots ccbot (de Common Crawl), google-extended et GPTbot.
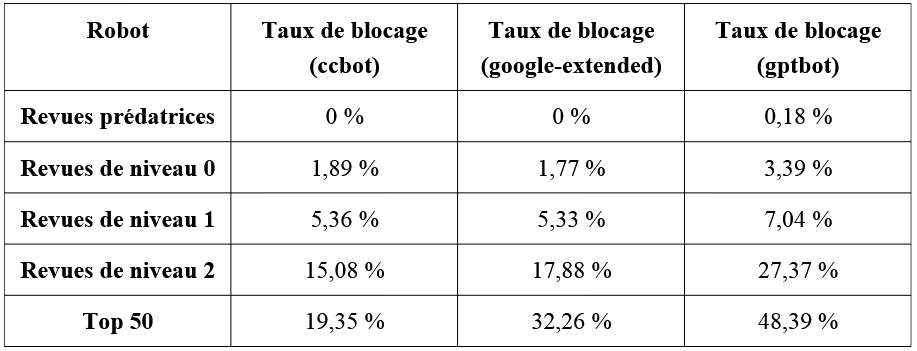
L’avis de l’expert
L’accès à l’information scientifique est un enjeu majeur pour les chercheurs, mais aussi pour les utilisateurs qui utilisent fréquemment les IAG. Il est frustrant de voir des blocages d’accès sans alternative de proposée, ni via une institution. Ce travail montre que cette problématique dépasse le cadre académique. Il apparait inimaginable que de mettre à disposition de l’information de piètre qualité à des personnes qui n’ont pas conscience de ce qu’elles consomment, en atteste les nombreuses sensibilisations sur l’utilisation de ces IAG. Les arrangements entre éditeurs et producteurs de LLM soulèvent des questions éthiques, notamment en ce qui concerne la qualité des données accessibles.
Le Forum « Jeunes Chercheuses, Jeunes Chercheurs »
Le Forum Jeunes Chercheuses, Jeunes Chercheurs (FJCJC) est un moment clé du congrès Inforsid, destiné à offrir aux doctorants une opportunité de présenter leurs recherches. Cette année, 18 participants ont exposé leurs travaux selon un format éprouvé : « Chevalier et Dragon ». Pour chaque présentation, un doctorant soulignait trois points positifs, le Chevalier, tandis qu’un autre formulait trois critiques constructives, le Dragon. Le public a ensuite pu interagir via des post-its pour poser des questions et remarques aux doctorants.
J’ai eu l’occasion d’être Chevalier pour Romain Stevens et ses travaux sur la recommandation de plans de carrière, et Dragon pour Marwa Alali et travaux sur l’exploitation de graphs pour la détection de cyber-menaces. J’ai trouvé l’exercice pas facile car le but est de trouver des éléments pertinents, ce qui demande un peu de temps d’analyse et de la recherche bibliographique. Pour Romain Stevens, j’ai du chercher dans les concepts abordés pour identifié des écarts entre le concept et ce qui était présenté. Quant au travail de Marwa Alali, j’ai surtout mis en avant l’importance de ces travaux de part le contexte dans lequel il s’inscrit. Pour mon passage, j’en retiens que mon sujet nécessite plus d’explications sur les concepts que j’aborde. On peut facilement oublier d’expliquer un terme parce qu’il nous parait évident puisque travaillant avec au quotidien.
Ce FJCJC était ma première opportunité de présenter le début de mes recherches et, bien que le stress de présenter ses travaux en 4 minutes soit plus que présent, l’exercice était très intéressant. C’est donc avec plaisir que je présenterais la suite de mon aventure doctorale l’année prochaine !

Et encore bien d’autres sujets à explorer…
“Éthique, Équité et Systèmes d’Information : construire un numérique responsable et inclusif”, tel était le thème de cette 43e édition d’Inforsid. Il illustre l’intention de la recherche sur les systèmes d’information de sortir de l’objectif d’optimisation, souvent central dans ce domaine. Cette évolution montre que l’informatique ne se limite plus à la technologie, mais s’engage dans une réflexion plus large sur son impact sur la société.
Pour ma part, cette première édition d’Inforsid est un succès. J’ai rencontré une communauté de doctorants aussi passionnants que passionnés. Cela renforce mon engagement avec mon laboratoire, le Laboratoire d’Informatique de Grenoble, et Néosoft, à progresser dans mes travaux mêlant données, systèmes d’information, et environnement.
Ressources
Akoka, J., Comyn-Wattiau, I., 2025. Gouvernance des données : vers un cadre conceptuel. Présenté à INFORSID 2025 : https://inforsid2025.sciencesconf.org/data/pages/actesINFORSID25_v10.pdf#page=183
Abraham, R., Schneider, J., & Vom Brocke, J., 2019. Data governance: A conceptual framework, structured review, and research agenda. International journal of information management, 49, 424-438.
Bibliothèque universitaire de La Rochelle Université, 2022. Bibliométrie et impact de le recherche, url : https://bu.univ-larochelle.fr/lappui-a-la-recherche/valorisation-de-la-recherche/bibliometrie-et-impact-de-la-recherche-2/ (accédé le 18/06/2025).
Khatri, V., & Brown, C. V., 2010. Designing data governance. Communications of the ACM, 53(1), 148-152.
Viseur R., 2025. Analyse de l’impact des restrictions d’accès à l’information scientifique sur la qualité des données d’entraînement des LLM. Présenté à INFORSID 2025 : Lien vers l’article : https://inforsid2025.sciencesconf.org/data/pages/actesINFORSID25_v10.pdf#page=151
Les résultats du baromètre MetraData : https://drive.google.com/file/d/1Gx3-mE0eRdizmIw4npObeXKBLm1daX3t/view
Article Néosoft sur NéoGen : https://www.neosoft.fr/neogen-by-neosoft/