
Maîtriser ses dépenses AWS : un retour d’expérience de l’AWS Summit 2025

Sommaire
- Budgets et anomalies : les premiers gardiens de vos finances
- Mieux voir pour mieux gérer : analyser ses coûts
- Kubernetes + Spot : duo gagnant pour le compute
- Le bon dimensionnement, une science (presque) exacte
- Graviton : performant et économique
- DynamoDB : bien choisir son mode de capacité
- Coûts réseau : les mauvaises surprises
- Optimisations cachées : API, logs, stockage
- Anticiper les coûts d’un nouveau projet
- Une culture FinOps à construire
Le cloud, c’est la promesse de la flexibilité, de la scalabilité, et d’une innovation plus rapide. Mais soyons honnêtes : sans un bon contrôle, la facture peut vite grimper.
Lors du AWS Summit Paris 2025, une des conférences a justement abordé un sujet sensible mais essentiel : la maîtrise des coûts sur AWS. Outils, retours d’expérience, erreurs à ne pas reproduire… Chez Néosoft, nous avons eu la chance d’y assister, et ce qu’on a entendu faisait clairement écho à ce que l’on retrouve dans nos missions FinOps chez nos clients. On a donc décidé de vous résumer ici, les optimisations efficaces, les leviers actionnables, et les approches que l’on trouve utiles pour reprendre le contrôle sur ses dépenses AWS sans freiner l’innovation.
Budgets et anomalies : les premiers gardiens de vos finances

Dans toute démarche FinOps, la première étape incontournable consiste à mettre en place des garde-fous efficaces pour protéger votre budget et garder le contrôle sur vos dépenses. C’est un principe largement partagé et qui a été illustré par le retour d’expérience des intervenants lors de cette conférence. Afin de concrétiser cette approche, les équipes ont misé sur des solutions AWS très efficaces pour instaurer une première couche de surveillance budgétaire.
AWS Budgets
Cet outil vous permet de surveiller en temps réel les coûts générés par vos ressources. Vous pouvez:
- Réagir rapidement dès qu’un seuil critique est atteint, vous permettant d’anticiper et de gérer au mieux vos dépenses.
- Définir clairement des seuils d’alerte sur vos dépenses, mensuellement ou par projet.
- Créer des rapports programmés afin d’avoir un suivi régulier et précis.
AWS Cost Anomaly Detection
Boosté par l’intelligence artificielle et le machine learning, cet outil vous aide à:
- Identifier rapidement et réduire les factures imprévues grâce à des alertes automatiques.
- Configurer facilement un abonnement d’alerte pour être immédiatement informé dès qu’une anomalie est détectée.
- Recevoir instantanément des notifications, facilitant ainsi une réaction rapide pour corriger les éventuelles dérives de coût.
Prenons l’exemple concret présenté lors de la conférence pour illustrer l’efficacité de ces outils : une hausse brutale de 808 % des coûts associés à AWS Step Functions a été repérée en seulement quelques heures. Grâce à une alerte rapide de Cost Anomaly Detection, une intervention immédiate des équipes a pu être mise en place, ce qui leur a permis de faire une économie substantielle. Sans cette vigilance automatisée, les conséquences financières auraient pu être bien plus importantes, générant du stress inutile aux équipes et potentiellement de lourdes conséquences économiques pour le projet.
En mettant en place ces deux outils de surveillance, vous établissez un filet de sécurité financier, garantissant à vos projets une maîtrise optimale de leurs coûts et une tranquillité d’esprit indispensable pour vous concentrer pleinement sur vos objectifs business.
Mieux voir pour mieux gérer : analyser ses coûts
Pour approfondir cette démarche, les intervenants ont mis l’accent sur une visualisation claire et adaptée permettant d’aller au-delà de la simple analyse technique des coûts. Pour cela, ils ont exploité des outils clés qui facilitent l’accès et la compréhension des données financières :
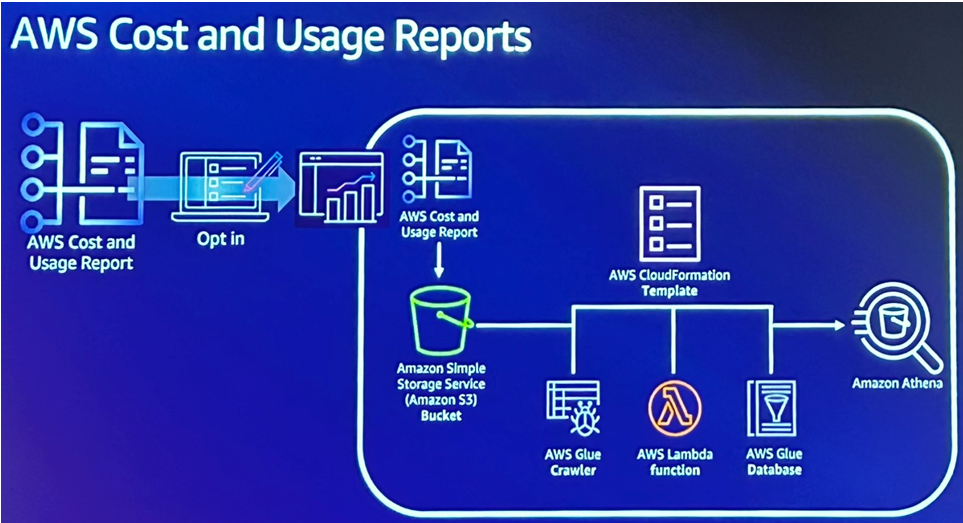
- Le Cost & Usage Report (CUR) élément central permettant d’obtenir des données précises et détaillées sur l’utilisation des ressources AWS et les coûts associés. L’exportation simplifiée de ces données facilite considérablement leur exploitation pour des analyses approfondies.
- Afin de renforcer cette analyse et surtout de rendre les données facilement compréhensibles par les équipes métier, leur choix a été d’intégrer les informations du CUR dans Apache Superset, une plateforme open source de Business Intelligence. Cette approche a permis de créer des tableaux de bord personnalisés, croisant ainsi efficacement données techniques AWS et indicateurs métier.
L’objectif était clairement affiché : améliorer la communication sur les coûts avec les équipes métier, afin qu’elles puissent prendre des décisions éclairées grâce à une visualisation centralisée et pertinente.
Kubernetes + Spot : duo gagnant pour le compute
Un autre levier fort d’optimisation présenté lors de cette conférence, concernait la gestion du compute via Kubernetes. Dans le cas présenté, l’essentiel de la charge (environ 90 %) reposait sur des clusters Kubernetes avec des workloads de diffusion vidéo très variables selon les moments de la journée.
L’optimisation s’est appuyée sur une stratégie en plusieurs étapes, progressivement mise en place :
1. Mise en place de l’autoscaling horizontal
Indispensable pour suivre les pics du soir et les creux de la nuit. Le scaling s’effectue chaque jour, permettant de multiplier par 3 à 15 le nombre de nœuds selon la charge. Sans cet ajustement, l’infrastructure aurait été massivement surdimensionnée en permanence.
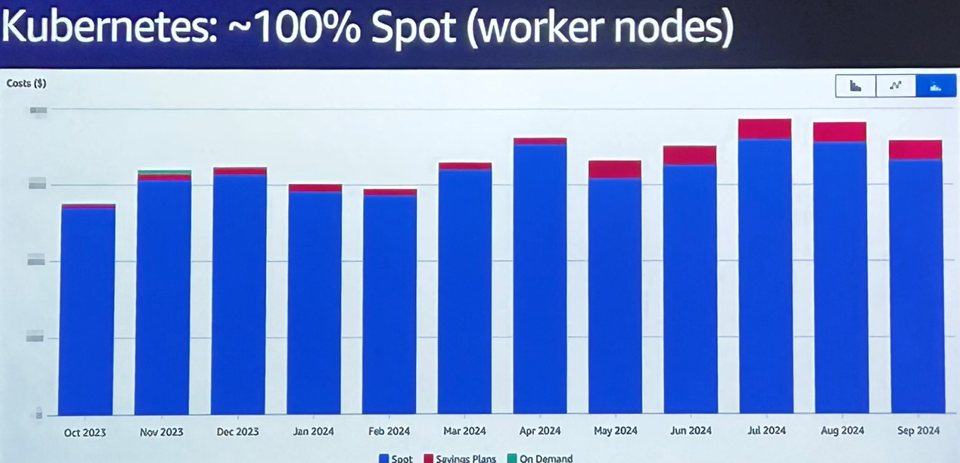
2. Basculer à 100 % sur des instances Spot pour les worker-nodes Kubernetes
Initiée progressivement, cette transition a été étalée sur plusieurs semaines. Une diversité de types d’instances EC2 a été utilisée pour maximiser la disponibilité, avec un fallback ponctuel en On-Demand si besoin.
3. Robustesse face aux interruptions Spot
Les interruptions quotidiennes ont été anticipées grâce à des termination handlers. Dès qu’une instance Spot est sur le point d’être révoquée (signal reçu 2 minutes avant), un script :
- Lance immédiatement une nouvelle instance.
- Éteint proprement l’application (drainage de requêtes, arrêt maîtrisé des services).
4. Temps de redémarrage optimisé
En créant des AMIs customisées, avec les composants Kubernetes et les images Docker de base déjà intégrée, les temps de boot sont passés de 5 à moins de 2 minutes. Cela garantit une résilience forte malgré la volatilité du Spot.
Résultat : une réduction de coût drastique sur la couche compute, sans compromis sur la qualité de service. L’architecture absorbe les pics de charge et se contracte pendant les périodes creuses, avec une réactivité et une stabilité maîtrisée.
Le bon dimensionnement, une science (presque) exacte
Dans l’optimisation cloud, on pourrait croire qu’il suffit de bien choisir son type d’instance dès le départ, mais dans la réalité, le bon dimensionnement se révèle bien plus nuancé. Lors du retour d’expérience partagé par les intervenants, une méthode pragmatique et itérative s’est souvent révélée plus efficace qu’une planification trop rigide.
L’équipe a donc adopté une approche empirique et progressive :
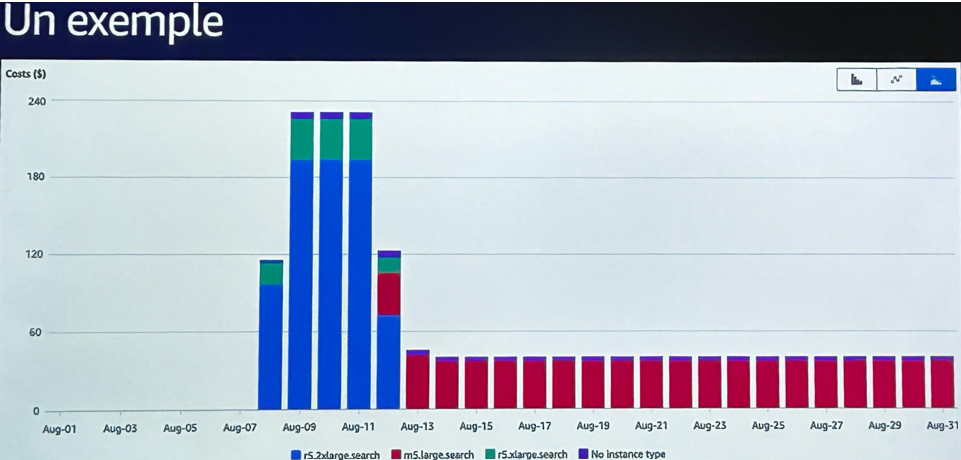
- Déployer d’abord en version “confort”, c’est-à-dire avec des instances volontairement surdimensionnées, pour garantir la stabilité initiale du service et observer la consommation réelle sur les premiers jours.
- Analyser les données de charge en conditions réelles pendant quelques jours, en croisant CPU, mémoire, réseau et latence.
- Affiner les ressources allouées à l’aide des recommandations générées par deux outils complémentaires :
- Trusted Advisor, qui signale les surprovisionnements évidents.
- Compute Optimizer, qui fournit des suggestions plus fines, basées sur les métriques historiques.
Ce processus d’ajustement post-déploiement a permis, dans plusieurs cas, de réduire significativement le coût des instances EC2. Comme évoqué lors de la session : « On laisse tourner quelques jours, on reçoit une alerte Cost Anomaly Detection, on regarde le comportement réel, puis on redimensionne. Résultat : une économie dès le quatrième jour. »
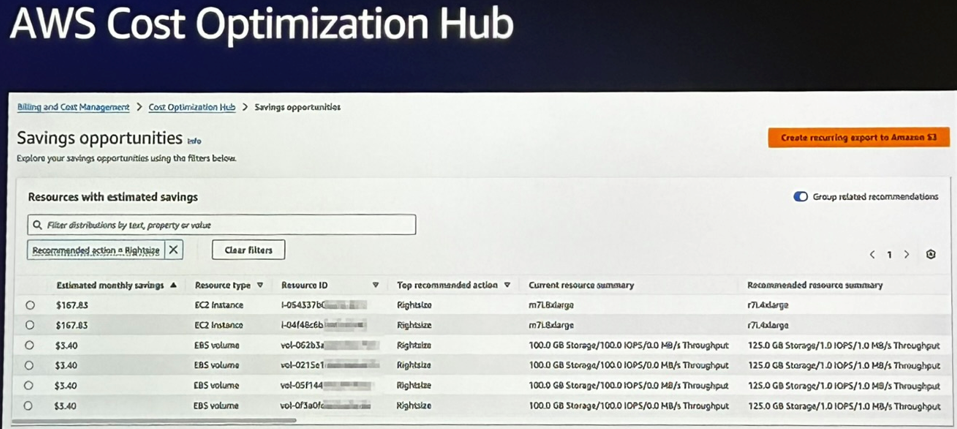
Cost Optimization Hub : tout centralisé
Pour centraliser cette logique d’optimisation continue, l’équipe s’est appuyé sur le Cost Optimization Hub. Ce tableau de bord unifié regroupe toutes les recommandations de Trusted Advisor et Compute Optimizer, et facilite leur mise en œuvre. Il permet notamment de prioriser les actions à fort impact et de suivre l’évolution des gains potentiels.
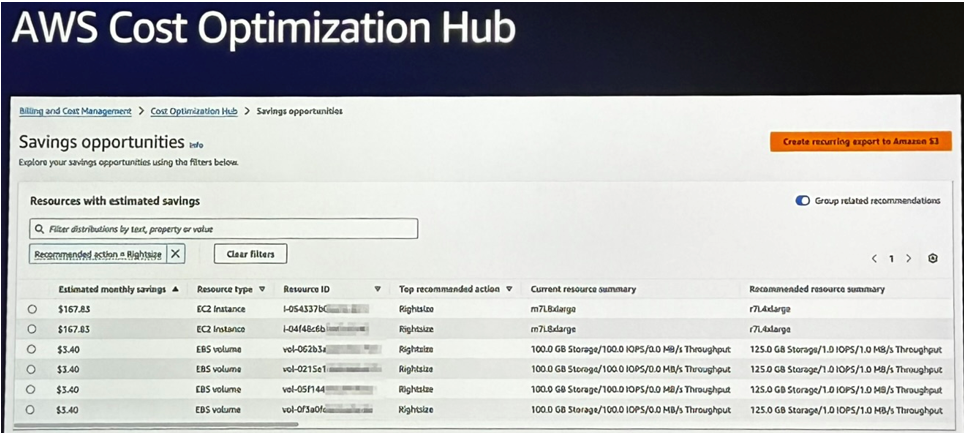
Résultat : une gestion proactive des ressources, où les décisions sont prises sur la base de données concrètes plutôt que d’hypothèses. Une démarche simple à mettre en place, mais qui demande rigueur et suivi dans le temps pour en tirer tous les bénéfices.
Graviton : performant et économique
Parmi les pistes d’optimisation mises en avant lors de la conférence, l’adoption des processeurs Graviton s’est montré être une stratégie intéressante. Basés sur l’architecture ARM, ces processeurs conçus par AWS offrent un excellent compromis entre performance, efficacité énergétique et coût, ce qui en fait une alternative de plus en plus crédible face aux architectures “classiques”.
Des migrations faciles… quand c’est possible
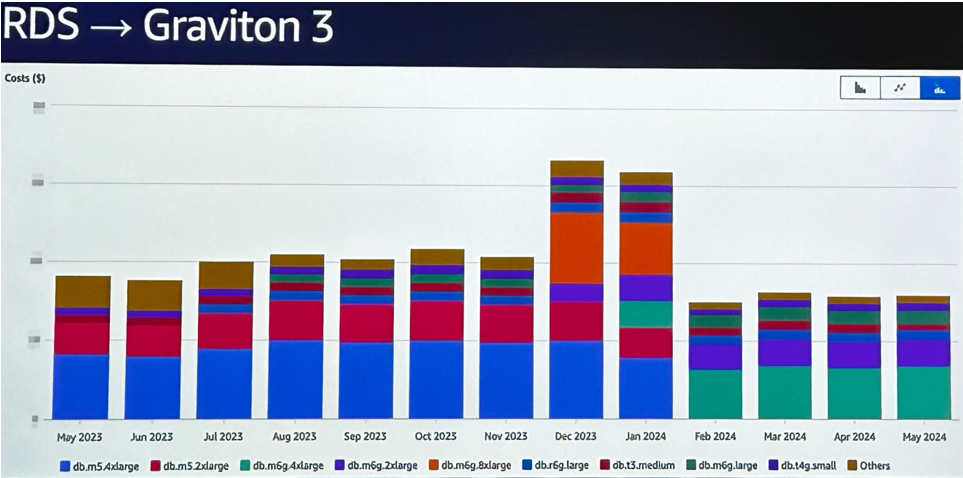
L’équipe a démarré sur Graviton 2 avec des workloads EMR. Et très souvent, la migration s’est faite en modifiant une seule ligne dans Terraform. Mais c’est vraiment avec l’arrivée des services managés compatibles Graviton (notamment RDS) que les gains se sont révélés les plus nets :
- En passant une base RDS d’Intel vers Graviton 3, l’économie constatée était de 15 à 20 %, malgré l’utilisation d’instances réservées.
- La migration a été quasiment transparente, sans refactor majeur.
Ce n’est pas toujours aussi simple
La compatibilité dépend fortement du stack technique :
- Sur des environnements Linux ou des apps en Go, Java, Python, la transition est généralement fluide.
- En revanche, pour les applications .NET ou Windows, un portage plus conséquent peut être nécessaire. Ce frein a été évoqué, même si dans ce cas précis, l’équipe n’était pas concernée.
Graviton est donc une solution à considérer dès lors que l’on peut rester dans un environnement Linux/ARM, notamment sur des services comme Lambda, EC2, ECS, ou RDS.
Conclusion : Graviton s’est imposé comme un levier de performance et de réduction de coûts très accessible, particulièrement adapté aux environnements modernes conteneurisés ou aux bases de données managées.
DynamoDB : bien choisir son mode de capacité
DynamoDB est une solution NoSQL entièrement managée, dont les coûts peuvent rapidement grimper si elle n’est pas utilisée avec discernement. Lors de la conférence, un retour d’expérience très complet a mis en lumière les subtilités de gestion de capacité, de stockage, et de réservation, avec un message clair : les vraies économies passent par une utilisation adaptée au contexte.
Trois leviers principaux ont été évoqués pour adapter finement la consommation aux besoins réels des applications :
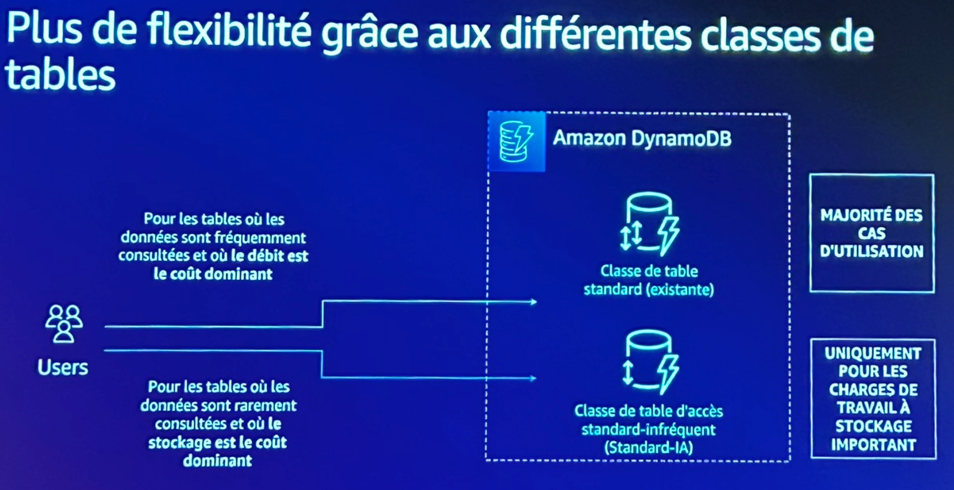
1. Mode On-demand
Idéal pour les phases de lancement ou les charges très variables, le mode On-demand vous évite d’avoir à prédire l’activité à l’avance. Vous ne payez que pour ce qui est consommé, ce qui en fait une bonne option pour :
- Les projets en démarrage.
- Les pics de trafic imprévisibles.
- Les environnements de test ou de développement.
2. Mode Provisionné avec Autoscaling
Dès que les charges deviennent plus prévisibles, ou une fois que le comportement des requêtes est bien compris, passer en Provisionné avec Autoscaling permet d’optimiser davantage. Cela permet :
- De définir des seuils planchers et plafonds de capacité.
- D’ajuster dynamiquement la capacité allouée selon la demande.
- De réduire les coûts en lissant les pics d’usage.
3. Classe de stockage Infrequent Access (IA)
Enfin, pour les tables peu sollicitées — historiques, logs, archives, etc. — la classe IA permet de diviser les coûts de stockage. Ce mode est particulièrement intéressant lorsque :
- Les données doivent être conservées mais sont rarement consultées.
- Votre coût de stockage dépasse 50% de votre coût de débit (lectures/écritures).
Exemple concret : une application en On-demand générait des coûts élevés, mais après analyse de la charge, elle a été basculée en Provisionné avec Autoscaling → résultat : coûts divisés par 3 à 4.
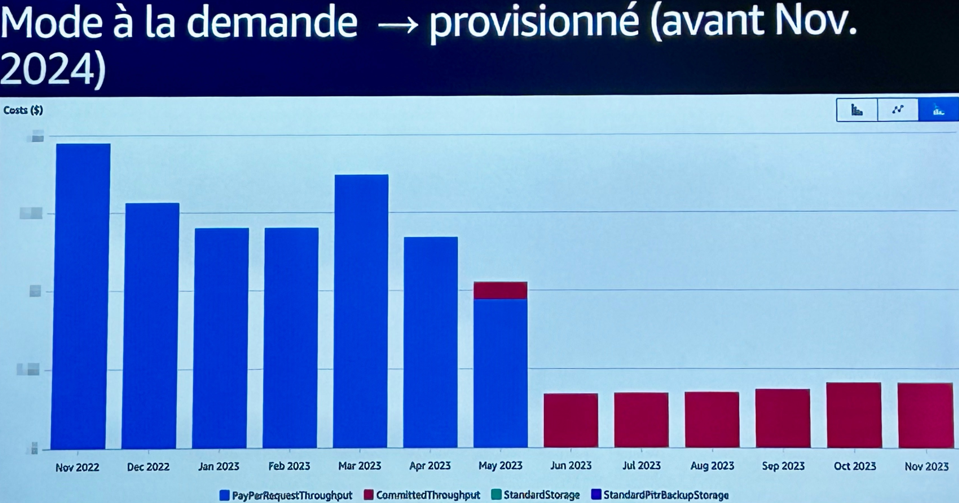
Stockage : la vraie surprise
L’autre enseignement clé : ce ne sont pas toujours les requêtes qui coûtent le plus. Dans certains cas, les coûts de stockage et de backup dépassaient ceux des lectures/écritures.
« On avait plein de vieilles données dans nos tables DynamoDB. On a fait du tri, supprimé ce qui ne servait plus, et les économies ont été immédiates. »
Et pour les données à conserver mais rarement utilisées, la classe de stockage Infrequent Access (IA) s’est imposée. Facile à activer, elle permet une baisse de coût sans compromis sur les performances.
Conclusion : DynamoDB n’est pas un “set and forget”. Avec un peu de rigueur dans les choix de capacité, de stockage, et de nettoyage, on peut facilement réduire la facture sans impacter la résilience ou les performances.
Coûts réseau : les mauvaises surprises
Dans une démarche FinOps, certains postes de dépenses passent longtemps sous le radar, jusqu’à ce qu’ils explosent. Le réseau fait justement partie de ces coûts cachés, souvent sous-estimés, mais qui peuvent peser lourd sur la facture AWS.
La bonne nouvelle : les leviers d’optimisation sont nombreux, souvent simples à mettre en œuvre.
Identifier les zones de fuite
Un exemple parlant : des VPC endpoints avaient été créés pour tous les comptes de production, sauf un, de type « sandbox », utilisé ponctuellement. Le jour où ce compte a commencé à générer du trafic, tout est passé par la NAT Gateway, avec à la clé une explosion des coûts réseau.
Réflexe à adopter : créer les VPC endpoints pour S3 ou DynamoDB, même dans les environnements secondaires. C’est à la fois plus économique et plus sécurisé.
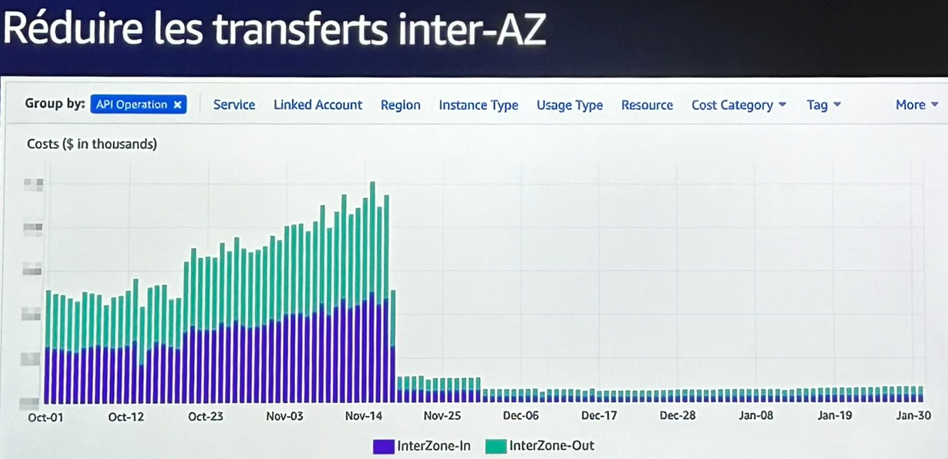
Refonte de l’architecture pour éviter les transferts inter-AZ
L’exemple le plus marquant est sans doute celui du trafic inter-AZ : des microservices échangeaient des fichiers vidéo entre différentes zones de disponibilité, chaque fois qu’un utilisateur faisait une demande.
Résultat : des coûts de transfert inter-AZ massifs… pour chaque segment vidéo, parfois plusieurs fois par utilisateur.
La solution a été de repenser l’architecture :
- Un utilisateur est désormais systématiquement servi dans une seule AZ.
- Le load balancer ne bascule sur une autre zone qu’en cas de défaillance.
- Les microservices communiquent en priorité dans la même zone, réduisant drastiquement les transferts facturés.
Supprimer ce qui ne sert plus
Comme toujours, un nettoyage régulier a permis de gagner rapidement :
- Suppression des NAT Gateway et des ELB inactifs, mais encore facturés.
- Réduction du trafic sortant via CloudFront, qui combine performance et économies.
Ces ajustements ont permis non seulement de réduire de manière significative la facture réseau mensuelle mais également d’améliorer la performance globale. C’est un bon rappel que, dans le cloud, chaque flux aussi petit soit-il compte et que l’optimisation ne concerne pas seulement le compute ou le stockage.
Optimisations cachées : API, logs, stockage
Toutes les optimisations FinOps ne se jouent pas sur des choix d’architecture ou de type d’instance. Certaines économies, souvent ignorées, se cachent dans les petits gestes techniques du quotidien. Les intervenants de cette conférence AWS, ont mis en avant une série de bonnes pratiques “cachées”, qui, mises bout à bout, peuvent représenter un vrai levier de réduction des coûts.
Côté stockage et conteneurs : faire le ménage
Le stockage, en particulier dans les environnements conteneurisés, est un terrain fertile pour les optimisations “oubliées” :
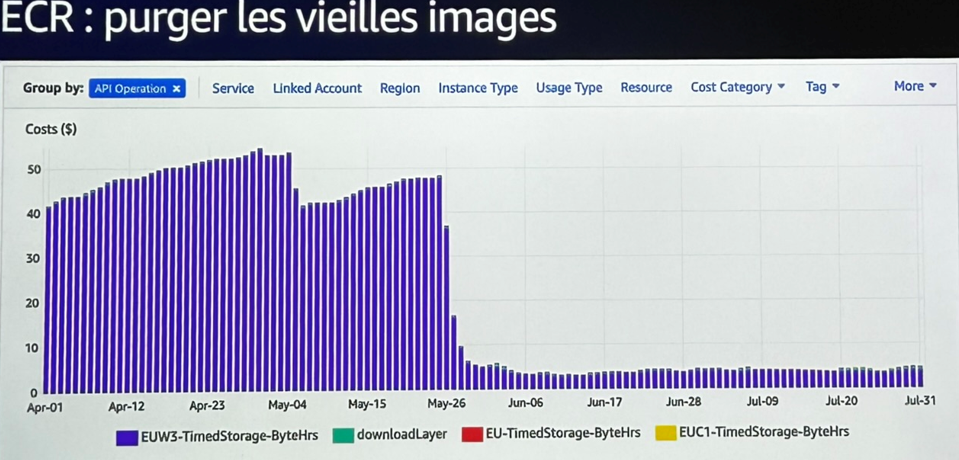
- Suppression automatique des images Docker inutilisées dans Amazon ECR : les images Docker s’accumulent au fil du temps, souvent sans jamais être nettoyées. En activant la rétention automatique, l’équipe a supprimé des centaines d’artefacts inutiles, réduisant immédiatement la facture sans risque pour la prod.
- Nettoyage ciblé des logs CloudWatch : certains logs n’avaient plus de valeur après quelques jours. Leur suppression ou le passage en classe Infrequent Access a permis d’économiser jusqu’à 50 % sur l’ingestion et la conservation sans perdre d’information essentielle.
Côté monitoring : ajuster le niveau de détail
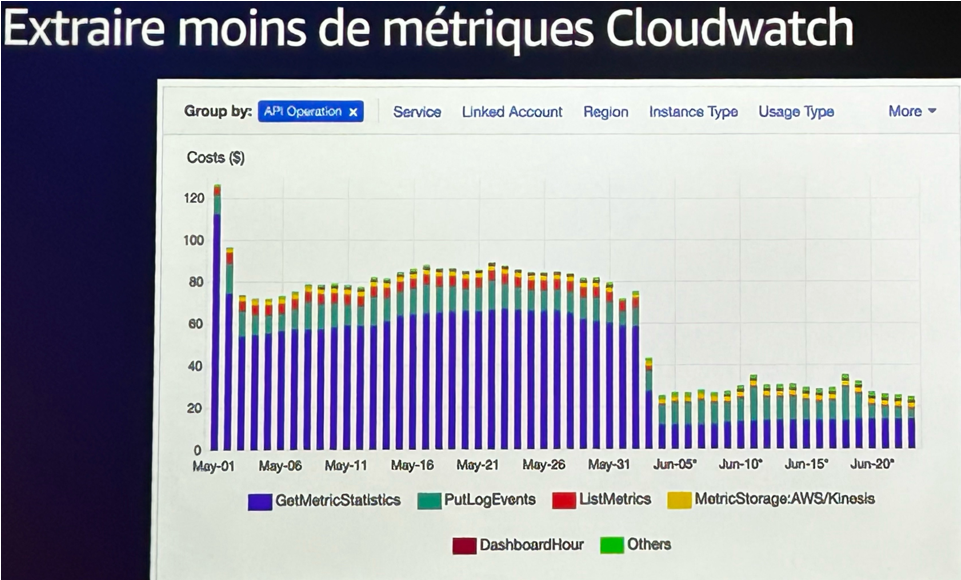
Les métriques sont utiles jusqu’à ce qu’elles deviennent superflues. L’équipe utilisait Prometheus et Grafana comme observabilité principale, mais récupérait quand même beaucoup de métriques depuis CloudWatch.
Résultat : environ 80 $ par jour rien que pour des métriques non visualisées. Un audit des dashboards CloudWatch leur a permis de révéler les métriques inutilisées ou redondantes. Leur désactivation a permis :
- De réduire la volumétrie de données collectées.
- De limiter le nombre d’objets stockés, donc la facture associée.
Côté API : regrouper, éviter, simplifier
Dernier levier souvent oublié : les coûts liés aux appels API.
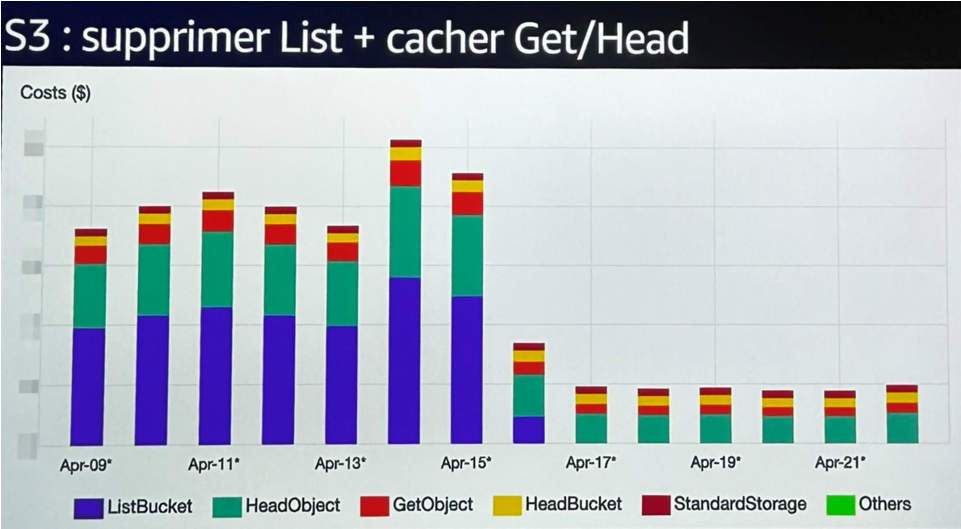
- Sur S3, une équipe a découvert que la majorité des coûts venaient des appels ListBucket et HeadObject. En cause : une vieille librairie validant chaque « dossier » de façon récursive, comme si S3 était un système de fichiers classique. En supprimant cette logique, et en ajoutant un peu de cache, ils ont économisé une part non négligeable de leur facture.
- Sur SQS, le passage de la suppression unitaire des messages à l’API batch a divisé les coûts par trois, simplement en regroupant les actions par lots.
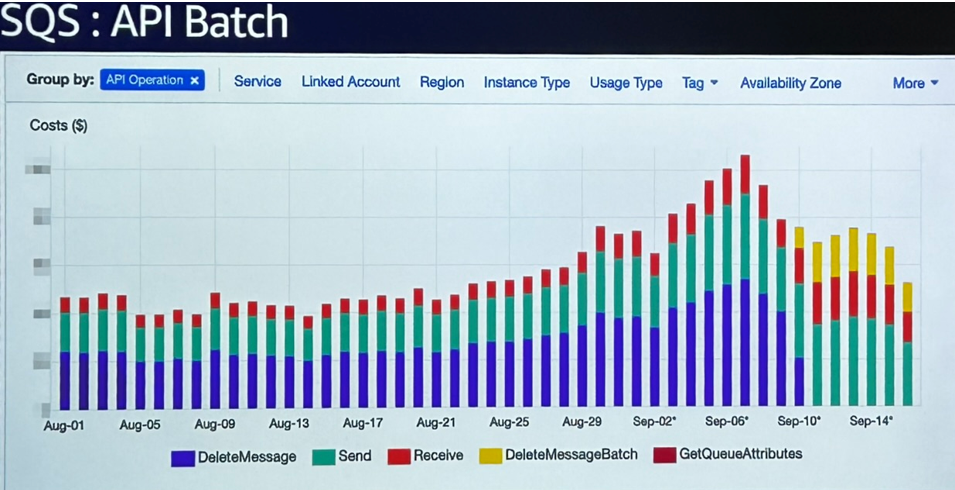
Résultat : Ces ajustements discrets ont permis une réduction significative des coûts invisibles à l’œil nu, mais qui s’accumulent jour après jour. Ce type d’optimisation n’est pas toujours prioritaire, mais peu facilement faire baisser la facture sans toucher à l’architecture.
Anticiper les coûts d’un nouveau projet
Avant même d’écrire la première ligne de code, une question revient systématiquement : combien ça va coûter ? Et c’est une question qu’il faut se poser très tôt, car les choix techniques pris au démarrage ont un impact direct sur la facture… et parfois sur la pérennité du projet.
Lors de la conférence, une démonstration en live a été faite à partir d’un cas concret : concevoir une nouvelle API HTTP, avec du traitement côté Lambda et une base DynamoDB.
Le projet simulé comportait :
- API Gateway (en frontal),
- AWS Lambda (traitement logique, en Go sur Graviton),
- DynamoDB (mode On-demand),
- 500 millions de requêtes / mois, avec une taille moyenne de réponse de ~17 Ko.
Résultat de l’estimation : environ 1800 $ / mois, un chiffre jugé cohérent par rapport à d’autres projets similaires. Mais surtout, une base de discussion avec les équipes produit, pour juger la viabilité du projet, le ROI attendu et ajuster les choix techniques en fonction.
Migration Step Functions : le bon choix au bon moment
Autre exemple d’optimisation en phase de run : une Step Function en mode Standard, utilisée pour synchroniser des microservices, générait une dépense de 25 $/jour à elle seule. En creusant, l’équipe s’est rendu compte qu’elle pouvait fonctionner en version Express, bien plus adaptée à sa fréquence et à son usage court.
« On a détruit la State Machine Standard, recréé une Express… et le coût a pratiquement disparu. »
> Économie immédiate, sans perte fonctionnelle. Ce cas illustre parfaitement l’intérêt de questionner ses choix initiaux à la lumière des usages réels.
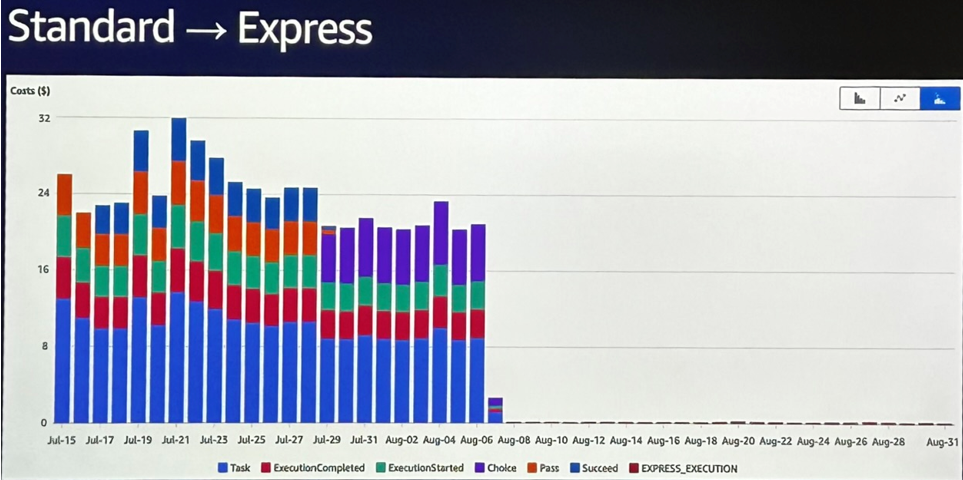
Conclusion : estimer les coûts dès la conception, c’est éviter les mauvaises surprises… mais c’est aussi un moyen d’aligner les décisions techniques avec les objectifs produit et business. Et grâce aux outils AWS comme le Pricing Calculator, Step Functions Express, ou encore Graviton, ces choix deviennent concrets, chiffrés — et surtout maîtrisés.
Une culture FinOps à construire
Au-delà des outils, des métriques ou des optimisations techniques, ce qui ressort avec force des retours d’expérience partagés, c’est que le FinOps n’est pas une discipline réservée aux experts cloud ou à la finance. C’est une culture, un état d’esprit collectif, qui se construit dans le temps.
Une approche transverse
Les intervenants l’ont rappelé : ce qui fait la différence, ce n’est pas d’avoir “une personne FinOps” dans l’organisation, mais que chaque acteur prenne conscience de son rôle dans la maîtrise des coûts. Cela commence par des actions simples :
- Former les équipes techniques à la lecture des coûts AWS, des dashboards Cost Explorer ou Budgets.
- Intégrer des KPIs non-fonctionnels dans les projets, comme le coût par API call ou par utilisateur actif.
- Rendre les coûts visibles, que ce soit via des dashboards partagés avec PowerBI, des revues régulières et même des alertes budgétaires.
L’idée, c’est de ne plus parler de coût en fin de projet, mais dès la phase de design.
S’appuyer sur une expertise dédiée
Pour accompagner cette transformation, certaines équipes s’appuient sur des profils ou des partenaires FinOps. Leur rôle : structurer la démarche, identifier les gains rapides, mettre en place les bonnes pratiques et fédérer les acteurs autour d’un objectif commun.
Ce n’est pas une armée de consultants. C’est un accompagnement ciblé, qui permet d’avancer plus vite sans alourdir les équipes internes.
Chez Néosoft, ce type de service, nous avons pu le mettre en place chez plusieurs de nos clients à travers nos prestations FinOps, avec toujours le même objectif : rendre les coûts compréhensibles, pilotables, et alignés avec les enjeux métiers.
Conclusion
Ce retour d’expérience du AWS Summit 2025 montre bien que maîtriser ses coûts dans le cloud, ce n’est pas une contrainte, c’est un avantage compétitif.
Avec les bons outils, les bons réflexes, et une vraie culture FinOps partagée entre tech, métier et finance, il est tout à fait possible de concilier innovation continue et dépenses maîtrisées.
AWS met à disposition tous les leviers techniques. Mais comme souvent, la vraie valeur vient de la façon dont on les utilise.