
Knime : bien plus qu’un ETL moderne

Sommaire
- Présentation
- Utilisations
- Knime Server : mise en pratique
- Notre avis sur l’outil
- Bonnes pratiques
- Retour d’expérience
Focus sur Knime, l’outil couplant Data Engineering et Data Science afin de réaliser des workflows complets. Vijaya et Kyllian, Data Engineers au sein du groupe Néosoft vous présentent Knime et ses nombreuses fonctionnalités.
Présentation
La plateforme d’analyse KNIME, permet de réaliser des workflows, c’est à dire un ensemble de tâches à partir d’une input. A l’instar d’outils comme Apache Nifi ou Streamset, KNIME s’inscrit dans la dernière génération des ETL. S’il on observe le résultat du nombre de recherches Google, on constate que KNIME égale Nifi de mai 2021 à mai 2022.
Chaque tâche qui compose le workflow est réalisée par un node, plusieurs nodes pouvant être organisés sous forme d’un composant. Le langage java est à l’origine de la construction de KNIME ainsi que de l’exécution et du développement des nodes. L’outil est disponible en version Windows, Linux ou Mac (client lourd), mais également sur Azure et AWS (serveur + client léger).
Enfin, les afficionados de la baleine aux conteneurs seront heureux puisque l’outil dispose d’une image sur le Docker Hub (client léger).
KNIME se présente comme ouvert à l’innovation. Il est possible de développer nos propres nodes. La plateforme est complétement open-source. Le code source est disponible sur Github depuis 2006 et a fait l’objet de plus de 350 commits de mai 2021 à mai 2022 grâce à ses 37 contributeurs à l’échelle mondiale.
La communauté des utilisateurs participe beaucoup à l’utilisation de l’outil. Elle est mise à contribution dans le KNIME Hub qui regroupe des nodes, composants et workflows mis à disposition par l’entreprise KNIME ainsi que par la communauté. À l’heure actuelle, plus de 4 000 nodes, 800 composants, et 10 000 workflows sont disponibles sur le KNIME Hub. Un forum, est aussi à disposition sur lequel les membres s’entraident.
Une plateforme riche en fenêtres
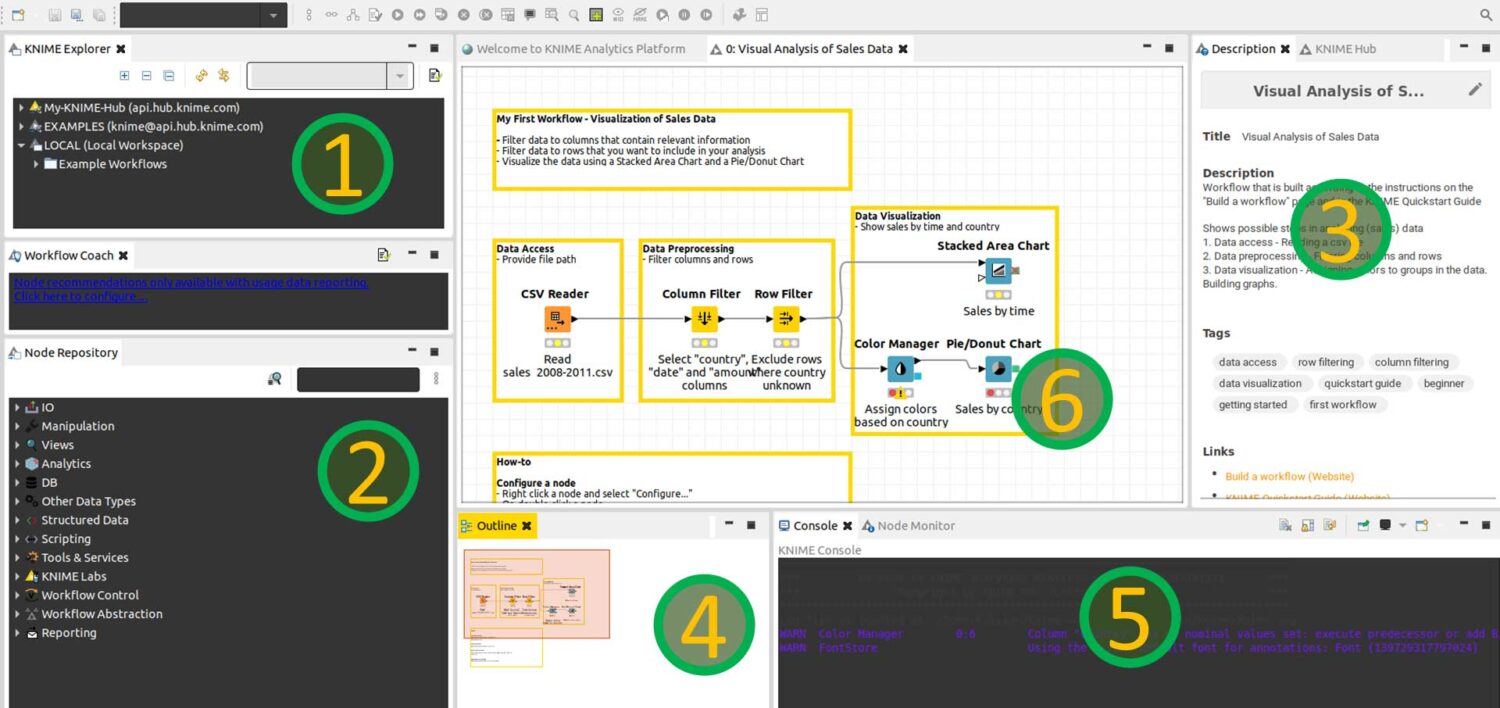
L’interface de la plateforme est composée de 6 fenêtres :
- Un explorateur de fichier qui permet notamment de transférer facilement les workflows vers le KNIME Hub
- Un répertoire dans lequel on va chercher les nodes
- Une description du workflow ou des nodes qui peut être réalisée par l’utilisateur
- La carte globale du workflow ainsi que la délimitation de ce que l’on voit
- Une console
- L’espace de travail, ou workflow
Tout au long de l’article Vijaya, data engineer et utilisatrice expérimentée de l’outil, approfondira certaines notions abordées dans cet article :
Ces fenêtres sont pour la plupart communes à tous les ETL sur le marché, notamment, l’espace de travail, la bibliothèque (ou palette) des nodes, l’arborescence de travail et la fenêtre des logs. La première subtilité de KNIME dans sa présentation se trouve au niveau de l’arborescence qui ne nous permet pas de remonter au delà de l’espace d’un projet.
Utilisations
L’outil permet de travailler la Data Science sous différents prismes. Ainsi il est possible de faire de la visualisation de données, l’utiliser comme un ETL, mais également de faire du Machine Learning (ML). À propos du ML, lors du data connect France qui s’est tenu le 27 avril 2022, Christophe Molina (Data Scientist) nous décrivait comment il a fait du Deep Learning et même du Transfer Learning avec l’outil KNIME.

La deuxième subtilité de KNIME se retrouve au niveau des nodes. En effet, les nodes sont bien plus nombreux que chez d’autres ETL notamment Alteryx et DataStage, ce qui peut perdre le développeur. Chaque node a un but spécifique et la documentation sur internet permet de nous y retrouver. Le nombre est en cohérence avec la volonté de l’outil de décomposer au maximum les traitements, apportant plus de souplesse à l’utilisateur au prix d’un développement plus coûteux. Ce découpage très fin permet un maintien plus facile de ce type de développement.
Vijaya, Data Engineer
Knime Server : mise en pratique
KNIME Analytics Platform est la version gratuite de KNIME. Il existe une version professionnelle, KNIME Server. Elle comprend trois offres : KNIME Server Small, Server Medium et Server Large. Plus d’informations sont disponibles sur le site de KNIME qui propose également une vidéo de présentation de KNIME Server.
Deux cas pratiques vont vous être présentés : une cartographie des compétences IT par Kyllian, puis une utilisation du node de filtre dans un contexte professionnel par Vijaya.
Cartographie des compétences IT par Kyllian
Kyllian va vous présenter son premier test de l’outil. Ce premier test de Knime concerne le traitement d’un jeu de données autour des compétences IT.
Présentation du dataset
Ce dataset est disponible sur la plateforme Kaggle et mis à disposition par le membre VMULLER. Ces données viennent de formulaires remplis par les membres de Kaggle durant le survey de 2018.

Le dataset tel qu’il est sur Kaggle (disponible ici).
Il s’agit d’un .json avec un titre de poste, un ensemble de compétences et une query. Le dataset comporte 1780 profils et un total de 754 compétences différentes.
Questions abordées
Pour donner du sens à ma réalisation avec KNIME, j’ai souhaité aborder 3 questions :
- Combien y-a-t-il de de profils par compétence ?
- Combien de compétences se retrouvent dans la même taille moyenne d’éventail de compétences ?
- Quelle est la taille moyenne d’éventail de compétences de chaque compétence ?
Mise en place du workflows dans KNIME Analytics Platform
Mon workflow est disponible à cette adresse.

Mon workflow comporte un premier sous-ensemble qui transforme le fichier .json en un tableau plus facilement utilisable par les autres nodes. Ensuite j’ai un ensemble d’espaces qui vont permettre le traitement des données selon la question posée pour enfin proposer un visuel.
Un node de filtre des données, j’exclue les données qui ont entre 1 et 100 profils associés
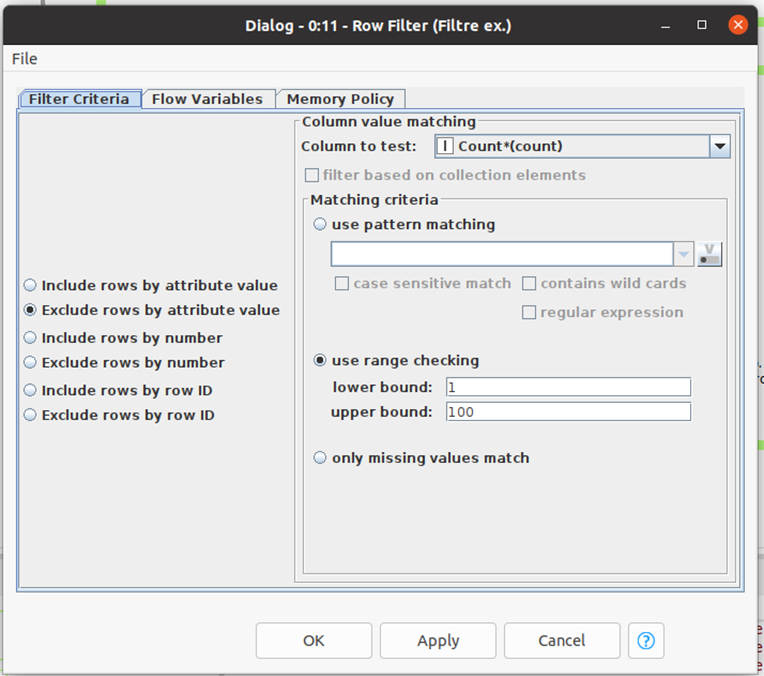
Le node que je présente ci dessus sert d’exemple pour la simplicité d’utilisation des nodes que j’ai utilisé pour mes analyses. Concernant la totalité des 4 000 nodes, je ne saurais dire s’ils sont tous aussi faciles d’utilisation puisque l’expérience utilisateur sur le node va dépendre du membre du KNIME Hub qui a développé le node.
Toutefois, ce node de filtre est aussi simple d’utilisation que les autres nodes de bases. Les nodes comportent des paramètres que l’utilisateur remplit avant de lancer sa phase de test. On retrouve ici l’intérêt des ETL qui sont simples d’utilisation et qui ne nécessitent pas de développements.
Contrairement à certains ETL, lors du développement, nous n’avons pas besoin d’utiliser des ‘break points’ pour arrêter le traitement en cours. KNIME offre la possibilité de lancer les nodes un à un (bouton dédié dans le menu) au lieu de lancer tout le job en entier. Ainsi cette souplesse de lancement des nodes est profitable dans le développement du workflow.
Je n’active que le node GroupBy, le sous-semble de la question 2 reste en stand-by.

Voici la représentation graphique des compétences présentes dans plus de 100 profils :

Parmi les compétences contenant plus de 100 profils, la première place est détenue par le python qui contient environ 500 profils.
Pour la question 2, voici une représentation graphique zoomant sur les éventails de 1, 2 et 3 compétences.
Moins de 5 compétences sont uniques chez certains profils, ce qui augmente de plus de 500% dès lors que l’on recherche une compétence en plus chez d’autres profils.
À ma 3ème question j’ai souhaité apporter un peu de fantaisie à mon graphique en ajoutant de la couleur aux barres selon la valeur de ses dernières. Or, cette situation s’est avérée plus complexe que prévu. Il a fallu que je fasse un fichier csv de mon tableau, filtré sur les données que je souhaitais cibler, puis de ce fichier, faire un ensemble de manipulations pour avoir un dégradé de couleur.
C’est là que la force de la communauté intervient. Sans l’aide de deux membres du KNIME Forum, je pense que j’aurais mis beaucoup plus de temps que prévu pour réaliser le graphique. Nous avons échangé sur le forum (lien) et j’ai mis à disposition mon workflow sur mon espace KNIME Hub pour que les membre du forum puissent identifier le problème plus facilement.


D’ailleurs, tout cette chaîne de traitements du fichier csv a été encapsulée dans un composant. Il est juste à coté du node « CSV Writer » (en rouge).
La parole est a Vijaya qui va vous présenter comment elle a amélioré la performance d’un node de filtre en y ajoutant une expression régulière.
Utilisation du node filtre en situation réelle par Vijaya
Durant un cas en d’utilisation en entreprise, j’ai eu l’occasion d’utiliser le node de filtre qu’il m’a fallu challenger en y manipulant une expression régulière.
« En informatique, une expression régulière est une chaîne de caractères qui décrit, selon une syntaxe précise, un ensemble de chaînes de caractères possibles. » source : Wikipédia

J’inclus les lignes qui correspondent à l’expression régulière
Avec ce node, j’ai cherché à filtrer sur tous les comptes qui ont des caractères différents de IPI, CRP, ISI positionnés en 4ème position (après 3 chiffres). L’expression se compose ainsi :
- ^ = « le début de la ligne »
- \d{3} = « trois chiffres »
- ?! = « différent »
- | = « ou »
- * = « la suite ne nous intéresse pas »
Notre avis sur l’outil
L’utilisation de cette expression régulière m’a fait gagner beaucoup de temps de développement dans mon travail. Toutefois, bien que cela soit un gain de temps, il est important de signaler qu’un tel traitement nécessite d’y apporter une attention particulière en terme de maintenance.
Les +
Le maitre mot de l’outil, c’est la simplicité. L’idée de pouvoir configurer très facilement les nodes de son workflow est vraiment très intéressante et une agréable surprise.
L’organisation du workflow est très intuitive puisque l’on a juste à drag and drop nos nodes pour les mettre comme on le souhaite. On peut réajuster les flèches si leur trajectoires ne nous conviennent pas. Il est possible de découper son workflow pour une meilleure visibilité en regroupant des nodes sous un métanode ou un composant.
Il est possible de faire tourner un seul node à la fois au lieu de tout le workflow. Ce qui est un avantage considérable lors de modifications ou d’ajouts de nodes dans un workflow. Cela permet de laisser libre court à son imagination et réaliser très facilement des tests. Également, la configuration des nodes est très facile et l’on peut les interconnecter avec d’autres nodes juste en cliquant de la partie droite d’un node, vers la partie gauche d’un autre.
La rapide intervention des internautes pour le travail de Kyllian met en évidence que KNIME bénéficie d’une communauté très forte et qui s’entraide. Cet ETL est Open Source avec des utilisateurs proactifs dans l’amélioration continue de KNIME.
De plus, la forte diversité des tâches à disposition est très intéressante. Il est possible de travailler la donnée avec des prismes très différents : retraitement, nettoyage, exploration, visualisation, machine learning.
Les axes d’amélioration
L’outil nécessite une organisation dès le début du travail, en se projetant sur ce que l’on veux faire et encadrant les nodes dès que possible.
Il existe énormément de nodes différents (lien). Tout est découpé en tâches simples mais cela peutentrainer un traitement complexe pour finalement une opération qui devait être simple (exemple : prendre le dernier jour du mois précédent).
Passer les liens en fantôme. C’est à dire la possibilité de cacher le lien et ne le dévoiler que lorsqu’on clique sur son node d’entrée ou de sortie.Comme tout est découpé dans KNIME, lors de la création d’un champ, on ne peut pas le réutiliser tout de suite dans le même node (contrairement à Alteryx avec formule et DataStage avec le transformer). Par exemple, lors de la création du champ date dans un column expression, il faut créer un autre column expression après si l’on veux réutiliser ce champ.
L’interface n’est pas aux goûts de tout le monde.
Bonnes pratiques
Si vous souhaitez commencer à travailler avec KNIME, nous avons dressé pour vous une liste de bonnes pratiques pour optimiser votre expérience utilisateur :
- Rechercher des workflows déjà réalisés par la communauté : avec plus de 10 000 workflows à disposition, il est très probable que le KNIME Hub soit en mesure de vous proposer un workflow assez proche de ce que vous souhaiter accomplir.
- Un node = une tâche : voyez KNIME comme une chaîne de production, chaque node réalise une tâche. Avant de se lancer dans le développement, il faut pouvoir décomposer ce que l’on veut faire en tâches plus simples.
- Profiter de la force de la communauté : le KNIME Forum dispose d’une communauté d’utilisateurs dynamiques. Cela doit vous inciter à la solliciter dès que vous rencontrez un problème que vous n’arrivez pas à résoudre.
- Organisation de son espace de travail : le workflow peut vite devenir tentaculaire, ainsi pour plus de lisibilité et améliorer la compréhension de votre travail nous vous conseillons alors :
- de le écouper en inputs à gauche, chaînes de traitement au milieu, et outputs à droite.
- d’éviter de croiser les liens entre les nodes
- de regrouper ces nodes en métanodes quand cela est possible
- de renommer les nodes
Retour d’expérience
« De part mon expérience sur les ETL en général, je pense que KNIME a un fort potentiel dans les années à venir. La prise en main est facile, et KNIME concilie la facilité de développement avec les nombreuses possibilités d’utilisations. Par rapport aux autres ETL, cependant, je n’ai pas assez de recul ni d’expérience pour vraiment poser un jugement de valeur. Quelques mois d’expérience suffisent pour faire des traitements plus que décents mais n’ayant travaillé que sur la partie « donnée », je n’ai pas eu le temps d’approfondir les autres utilisations possibles. »
Vijaya, Data Engineer au sein de Néosoft Orléans
« Me concernant, j’ai beaucoup apprécié cette première expérience avec KNIME qui est également ma première expérience avec un ETL. Je ne saurais juger cet outil avec un autre de sa catégorie, mais la diversité des usages est très intéressante. J’ai également beaucoup aimé organiser mes nodes et documenter mon travail directement sur le workflow. Enfin, la facilité avec laquelle on partage son travail est, je trouve, l’autre force de l’outil. »