
DuckDB, l’essayer c’est l’adopter !

- DuckDB, qu’est ce que c’est ?
- Comment ca marche ?
- pour quels apports ?
- la preuve en image
- et augmentons le volume !
L’été est bien souvent une période un peu plus calme et donc plus propice pour former vos équipes, pour déployer une amélioration continue ou encore explorer de nouveaux outils data…
Alors, on aurait pu vous dire de faire du tri dans vos données, de vous atteler plus que jamais à la sécurisation de vos données, d’optimiser vos bases de données, de développer les compétences de vos collaborateurs ou encore de vous tourner plus que jamais sur des solutions Cloud… mais non. Place donc à notre Data Summer Tips 2023 : DuckDB !

Alors DuckDB , qu’est-ce que c’est ?
Repéré par @Kyllian Beguin, notre dénicheur d’outils Data, DuckDB est la trouvaille de l’été dans le domaine de la Donnée : C’est LE parfait outil pour traiter vos data on memory. Et dans le monde en constante évolution de l’analyse et de la science des données, c’est le bon allié qui permet de traiter un volume conséquent, rapidement en optimisant le processus de traitement des données.
Accélérer les requêtes analytiques avec une nouvelle approche de traitement des données
DuckDB est une base de données analytique open source qui se démarque par son approche de traitement des données orienté colonnes et sa capacité à tirer parti des fonctionnalités avancées des processeurs modernes. Et ce parti pris permet d’offrir de très bonnes performances lors de l’exécution de requêtes analytiques complexes sur de grands ensembles de données.
Et comment ça marche ?
L’une des caractéristiques clés de DuckDB est son architecture basée sur des colonnes, contrairement aux bases de données traditionnelles basées sur une structuration en lignes. Cette approche retenue par de grands éditeurs comme SAP avec sa solution HANA a déjà démontré des performances intéressantes.
Une architecture basée sur une structuration des données en colonnes pour des performances optimales
DuckDB stocke vos données en mémoire, de manière segmentée et par colonne. Cela signifie que seules les colonnes pertinentes pour une requête donnée sont traitées. Contrairement au stockage en ligne, ce choix permet d’éviter le traitement des données inutiles et d’accélérer considérablement les temps de réponse.
Exploitation optimisée des fonctionnalités matérielles de nos équipements modernes
Cet outil a été conçu pour tirer pleinement parti des fonctionnalités matérielles avancées des processeurs modernes, notamment de leur capacité de calcul vectoriel (SIMD) et du traitement parallèle. En exploitant ces fonctionnalités, DuckDB peut donc exécuter des opérations de traitement de données en parallèle en utilisant des instructions vectorielles pour accélérer les opérations mathématiques et logiques.

Pour quels apports ?
Cela se traduit par des temps de réponse plus rapides et des performances globalement améliorées, ce qui en fait une solution attrayante pour les applications analytiques gourmandes en calcul. Mais pas seulement :
Polyvalence et intégration
DuckDB offre une prise en charge de requêtes SQL complète, ce qui le rend compatible avec un large éventail d’outils et de frameworks d’analyse de données. Il peut même être intégré facilement dans les pipelines de données existants tout en l’utilisant avec des langages tels que Python, R et Java. Un large éventail qui permet de l’intégrer facilement dans les pipelines de données et les workflows existants. Une polyvalence que nous avons hâte de tester pour vérifier l’adoption par nos Ingénieurs BI et Data Engineer en substitution de pandas par exemple !
Performance et optimisation matérielle
DuckDB est spécialement conçu pour les requêtes analytiques complexes sur de grands ensembles de données. Son architecture en colonnes lui permet de traiter efficacement les requêtes en ne sélectionnant que les données nécessaires, tout en tirant pleinement parti des fonctionnalités avancées des processeurs modernes, à savoir le calcul vectoriel (SIMD) et le traitement en parallèle. Là encore, plus d’efficacité et de rapidité.
Open Source et Communauté
DuckDB est une base de données open source, c’est un avantage précieux dans ce contexte de recherche de solutions data hyperpersonnalisées : la Modern Data Stack. L’outil bénéficie également d’une communauté active de contributeurs et d’utilisateurs. Les 11 500 étoiles sur Github en font véritablement une valeur sûre et vous assureront du soutien et des ressources d’une large communauté pour partager et collaborer avec d’autres utilisateurs.
« En tant que Data Analyst ou Business Analyst, si vous disposez de nouveaux jeux de données dont l’intégration n’a pas encore été industrialisée, cet outil peut vous intéresser ! »
Nicolas HUCHE
Pas encore convaincu ? Alors testons-le !
Et pour le tester, rien de plus simple. Rendez-vous sur le site de DuckDB dans lequel vous trouverez un espace de démonstration. Et comme vous n’avez pas été formés à la solution depuis que vous avez découvert cette solution (ça ne fait que 2 minutes que vous lisez l’article), pas de soucis : une simple commande dans le prompt et vous pouvez démarrer. Si ces éléments ne sont pas suffisants, je vous invite à consulter le guide très complet disponible également sur leur site.
.help ou .example
Réaliser sa première analyse
Pour commencer, je vous propose une petite analyse de données en nous appuyant sur des data Open Source ce qui permet de charger des données publiques sans risque de confidentialité pour votre entreprise. Et pour cela, direction le site data.gouv.fr où je récupère un fichier CSV qui contient les données de consommation d’électricité et de gaz par Région et par Code NAF – taille du fichier 2,27Mo. Afin de simplifier les opérations qui vont suivre, je vous conseille de renommer le fichier avec un nom court – dans notre exemple : region.csv
Une fois dans la console, il n’y a plus qu’à charger les données avec une simple commande qui ouvre votre navigateur.
.files add
Une fois le fichier sélectionné, le chargement est immédiat et nous pouvons découvrir le résultat avec quelques commandes simples :
select count(*) from region.csv; select * from region.csv;
Première surprise, le résultat est extrêmement rapide, entre 300 et 400ms pour les 18 128 lignes, ce qui permet de poursuivre l’analyse sans difficulté. En consultant les métadonnées du fichier, le fichier contient les données par opérateur, année et catégorie de consommation donc je tente de simples comptages…
select operateur, annee, count(*)
from region.csv
where code_categorie_consommation in ('RES','PRO','ENT')
group by operateur, annee;
Et nouvelle surprise, ça fonctionne sans déclaration préalable de la structure ! Les colonnes du fichier ont été reconnues, et les données sont exploitables directement. Alors tentons quelques calculs.
Select operateur, nnée, cast(sum(conso) as decimal (15,2)) as consoMwh,
sum(pdl) as nbPtLivraison
from region.csv
where code_categorie_consommation in (‘RES’,’PRO’,’ENT’)
and nnée in (2019,2020)
group by operateur, année
order by nnée, sum(conso) desc ;
Une nouvelle fois, la requête fonctionne : les formats de données ont été reconnus automatiquement, les agrégats se font correctement, les conversions également, alors j’ai tenté un peu d’algorithme… et là aussi le test est réussi, le tout en 300 ms toujours…
select operateur, filiere, cast(sum(case when annee = 2019 then conso else 0 end) as decimal (15,2))
as consoMwh2019, sum(case when annee = 2019 then pdl else 0 end) as nbPtLiv2019,
cast(sum(case when annee = 2020 then conso else 0 end) as decimal (15,2))
as consoMwh2020, sum(case when annee = 2020 then pdl else 0 end) as nbPtLiv2020
from region.csv
where code_categorie_consommation in ('RES','PRO','ENT')
and annee in (2019,2020)
group by operateur, rollup(filiere)
order by operateur, sum(conso) desc;
Et dont voici le résultat associé :
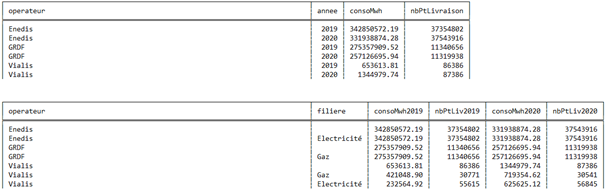
Donc en résumé, aucun manque jusqu’ici : on retrouve bien toutes les fonctionnalités attendues dans le respect des normes du langage SQL. D’autres tests ont confirmé le bon fonctionnement des sous-requêtes et des opérateurs ensemblistes si vous aviez des doutes.
union ; union all ; intersect ; …
Toujours pas convaincu ? Augmentons le volume !
L’objectif ici est de voir comment se comporte la solution avec plus de volume. Je passe donc au fichier de granularité commune qui une structure équivalente, mais il dispose d’un grain beaucoup plus fin. Le fichier contient 501 565 lignes pour 35 010 villes, ce que le count(*) m’indique en 4,3 secondes. On voit que le temps de réponse augmente…

Et en passant les mêmes requêtes que pour la maille région, on reste dans le même laps de temps d’environ 4 à 4,5 secondes. Un résultat honnête pour une telle volumétrie. En revanche, en comparant les résultats de nos fichiers, on constate quelques écarts de chiffres au niveau des opérateurs entre les 2 sources d’informations… mais là ça ne vient pas de l’outil !
select operateur, filiere, code_region, sum(consoRegion) as consoRegion,
sum(consoCommune) as consoCommune
from ( select operateur, filiere, code_region, cast(sum(conso) as decimal(15,2)) as
consoRegion, sum(0) as consoCommune
from region.csv
where code_categorie_consommation in ('RES','PRO','ENT')
and operateur in ('Enedis','GRDF','Vialis')
and annee = 2019
group by operateur, filiere, code_region
union all
select operateur, filiere, code_region, sum(0) as consoRegion,
cast(sum(consototale) as decimal(15,2)) as consoCommune
from commune.csv
where operateur in ('Enedis','GRDF','Vialis')
and annee = 2019
group by operateur, filiere, code_region) req
group by operateur, filiere, code_region
order by operateur, filiere, code_region;
Et dont voici le résultat associé :
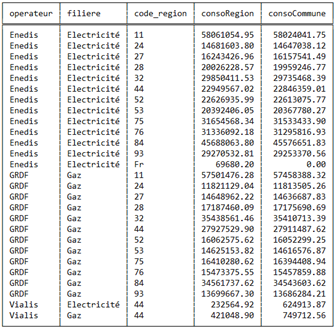
Fin du test et conclusion
« Ce qui m’a plu au travers de ce test, c’est la capacité à disposer d’un outil clé en main qui permet de faire des analyses de données en SQL en moins de 5 minutes et sans difficulté technique. La reconnaissance automatique de la structure et du format des données permet de se lancer immédiatement dans l’exploration sans perte de temps.
Comme abordé en début d’article, cette plateforme pourra s’intégrer dans votre Stack Data au cœur de vos pipelines de données, mais ce n’est pas son seul usage selon moi. En tant que Data Analyst ou Business Analyst, si vous disposez de nouveaux jeux de données dont l’intégration n’a pas encore été industrialisée, cet outil peut vous intéresser. »
Dans la plupart des cas, le choix d’un outil dépendra de vos besoins et attentes spécifiques en matière d’analyse de données, d’architecture et de préférences technologiques. Mais si vous recherchez un outil pragmatique, essayez DuckDB et ce n’est pas @Kyllian Beguin et @Nicolas Huche qui vous diront le contraire !
Rappel des atouts de DuckDB :
- sa puissance et sa performance
- sa communauté active
- sa polyvalence
- sa rapidité de prise en main