
DBT, le nouveau standard de transformation Data

Sommaire
- La Place de DBT dans un Pipeline ELT Moderne
- Revenons donc sur la description de DBT [data build tool]
- Les avantages concurrentiels de la solution DBT
- Conseil de l’expert & retour d’expérience
- Conclusion : l’avenir de la stack analytique moderne
Nous produisons tous les jours des données ! Que ce soit au travail (rapports, mails etc.) ou chez nous, simplement en scrollant… Et le volume est vertigineux. Pourtant, le véritable problème n’est pas le volume mais le vide. Aujourd’hui, on estime qu’entre 60 et 73% de ces données ne seront jamais utilisées, restant à l’état brut et sans valeur ajoutée. Pire encore, la mauvaise qualité de certaines de ces données coûte des milliards d’euros chaque année aux organisations.
Pour convertir ces montagnes de données brutes en un avantage concurrentiel, l’étape de la Transformation est critique. C’est là qu’intervient dbt (data build tool), l’outil qui a révolutionné la manière dont les Data Engineers et les Analystes travaillent, en rendant la transformation des données simple, fiable, testable, et gouvernée.
La Place de DBT dans un Pipeline ELT Moderne
La bataille entre ETL et ELT est un sujet de conversation qui revient fréquemment dans la Data. Le volume de données croît de manière exponentielle et les entreprises doivent choisir la meilleure approche.
Rappelons ce qu’est un ELT et sa différence avec ETL afin de comprendre le rôle de dbt dans cette usine.
Historiquement, le traitement des données suivait le schéma ETL. Cet acronyme signifie Extract Transform Load :
- Extraction : Les données sont extraites des sources (ex : fichiers)
- Transformation : Ces données sont ensuite chargées sur un serveur intermédiaire où l’intégralité des actions de nettoyage, d’agrégation et de jointure est effectuée. C’est un serveur qui doit être dimensionné pour gérer les pics de charge de calcul.
- Chargement [load]: Seules les données finales et transformées sont enfin chargées dans l’entrepôt de données (Data Warehouse).
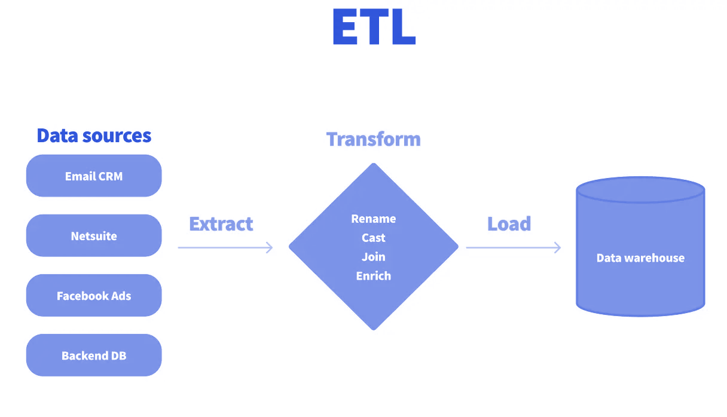
Un système ETL nécessite de maintenir et donc de payer un serveur de transformation séparé et capable de supporter les pics de charge. Seules les données transformées sont chargées dans le Data Warehouse, ce qui implique que chaque nouveau besoin nécessite de repartir à chaque fois de la source initiale. Puis ensuite de réitérer de nouvelles analyses sur les données brutes.
L’avènement des Data Warehouses Cloud comme Snowflake, Google BigQuery ou encore Amazon Redshift a changé la donne. Ces plateformes offrent une puissance de calcul et de stockage quasiment illimitée, facturée à l’usage.
Un système ELT va exploiter cette puissance simplement en plaçant la transformation des données après le chargement de ces dernières sur le Data Warehouse.
- Extraction : Les données sont extraites des systèmes sources.
- Chargement [Load] : Les données sont tout d’abord chargées intégralement dans l’entrepôt de données cloud, souvent dans un schéma dit « bronze » ou « brut ».
- Transformation : C’est la phase finale et la plus importante. La transformation est effectuée à l’intérieur du Data Warehouse lui-même, en utilisant sa puissance de calcul native via le langage SQL.
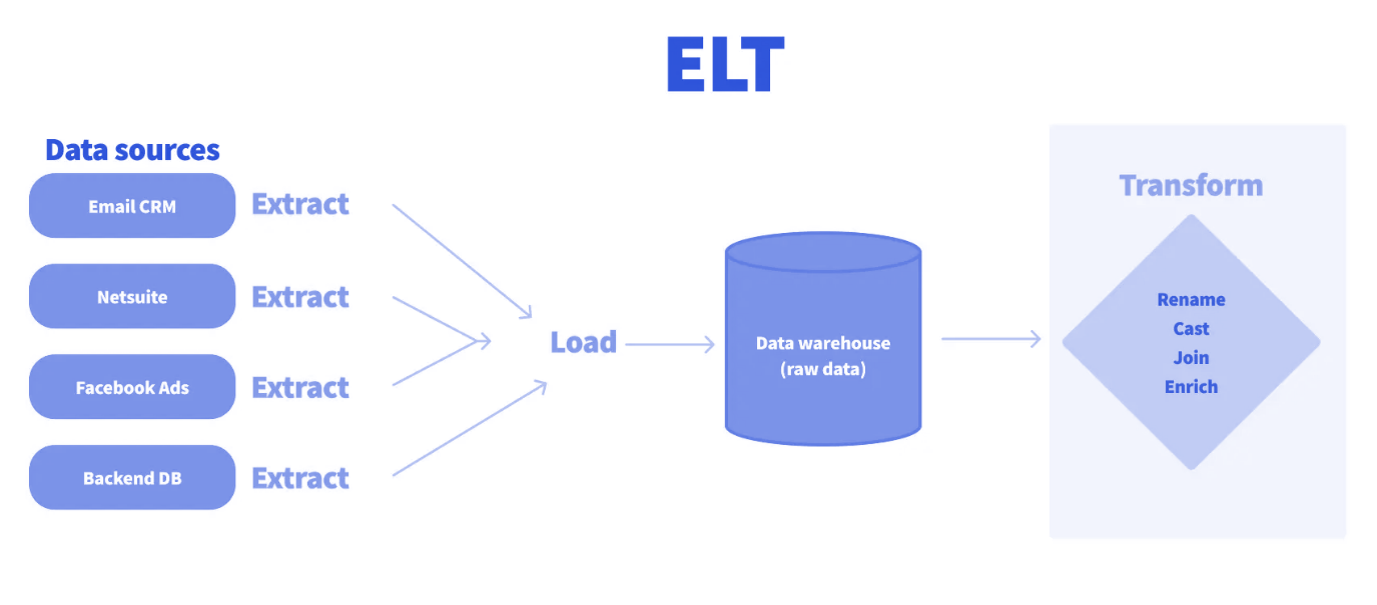
Ce que change cette approche ELT
Un ELT s’appuie sur la puissance de calcul en parallèle du Data Warehouse Cloud pour apporter rapidité et scalabilité dans le chargement et la transformation des données. Avec une approche Data Lake, l’un des avantages est de conserver toutes les données brutes. Cette méthode permet de créer simplement une nouvelle requête de transformation SQL pour les nouveaux besoins. Pour finir, on réalise des économies grâce à la suppression du serveur séparé tout en capitalisant sur le système de calcul cloud qui ne facture qu’en fonction de la volumétrie utilisée.
Cette approche est scalable et flexible. Elle permet donc aux organisations de travailler avec de plus larges datasets de manière efficace. En chargeant d’abord les données brutes dans le Warehouse, un ELT permet un modèle de données plus ouvert. Les analystes et les équipes de données peuvent accéder aux données et les transformer selon leurs besoins sans être bloqués par des processus trop techniques en amont. Cette démocratisation favorise une plus grande agilité et collaboration entre les équipes.
Vient donc le rôle de dbt dans un ELT: vous l’aurez compris, l’Extraction et le chargement (Load) sont gérés par des outils d’ingestion indépendants. Dbt intervient uniquement lors de la Transformation. Son rôle est d’utiliser les données brutes chargées dans le Data Warehouse et de les transformer en données prêtes à l’emploi à travers des “modèles” SQL.
Dbt recommande de structurer cette transformation en 3 “couches” (Staging, Intermediate, Marts). Ces couches s’inspirent de l’approche médaillon, qui elle-même utilise 3 couches principales. Dans cette approche :
- La couche Bronze va récupérer les données brutes nécessaires à notre besoin,
- La couche Silver nettoie ces données, les fusionne si besoin puis les met en conformité, avec toujours le principe du strict nécessaire pour l’analyse,
- Enfin, la couche Gold agrège les résultats et calcule les KPI pour fournir des données prêtes à être consommées par les outils décisionnels ou les utilisateurs.
Revenons donc sur la description de DBT [data build tool]
Dbt, autrement dit data build tools, est un outil de transformation de la data, comme son nom l’indique. Il ne s’occupe que de la partie transformation sans se soucier des phases préalables d’extraction ou de chargement. Une fois déployé, dbt s’exécute directement dans votre entrepôt de données (Data Warehouse). Avec l’avènement des solutions cloud, dbt a aussi développé sa propre version cloud (dbt Cloud) qui simplifie le déploiement, l’orchestration et la collaboration grâce à une interface web et des intégrations avancées.
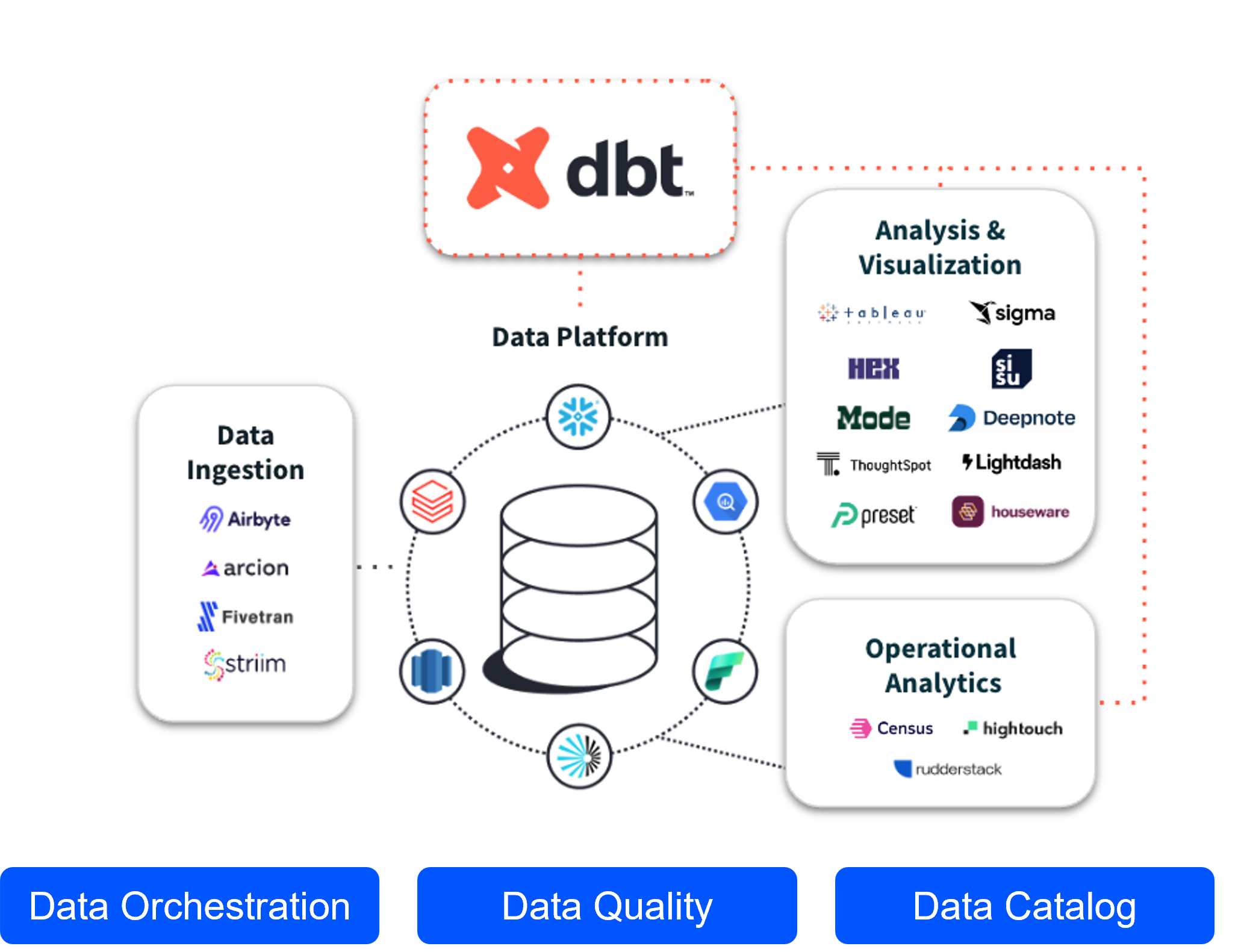
Focus sur les fonctionnalités clés de DBT
DBT comprend plusieurs fonctionnalités intéressantes :
- Versioning : dbt permet le contrôle de version pour toutes les transformations. Ce qui facilite le suivi des changements et la collaboration entre équipes. Cela garantit des transformations de données organisées et cohérentes.
- Automatisation et planification : Avec dbt, vous pouvez automatiser les processus de transformation, en veillant à ce que les données les plus récentes soient toujours disponibles pour l’analyse. Cela s’intègre parfaitement dans un flux de travail ELT, où la transformation se produit après que les données soient chargées dans l’entrepôt.
- Tests complets et documentation : dbt offre des capacités de test intégrées pour valider les transformations, ainsi que la génération de documentation intuitive ce qui vient ajouter les cordes « qualités et gouvernance » à son arc.
Focus sur l’approche DataOPS de DBT
Dbt Labs utilise un “framework” appelé ADLC (Analytics Development Lifecycle), un modèle inspiré du SDLC (Software Development Lifecycle), visant à instaurer des workflows matures pour l’analytics. C’est un principe simple qui vise à décrire un système analytique comme un logiciel. L’idée est d’appliquer les meilleures pratiques du DevOps (version control, CI/CD, testing, documentation) à l’ensemble de la stack analytique, pas seulement aux transformations de données.
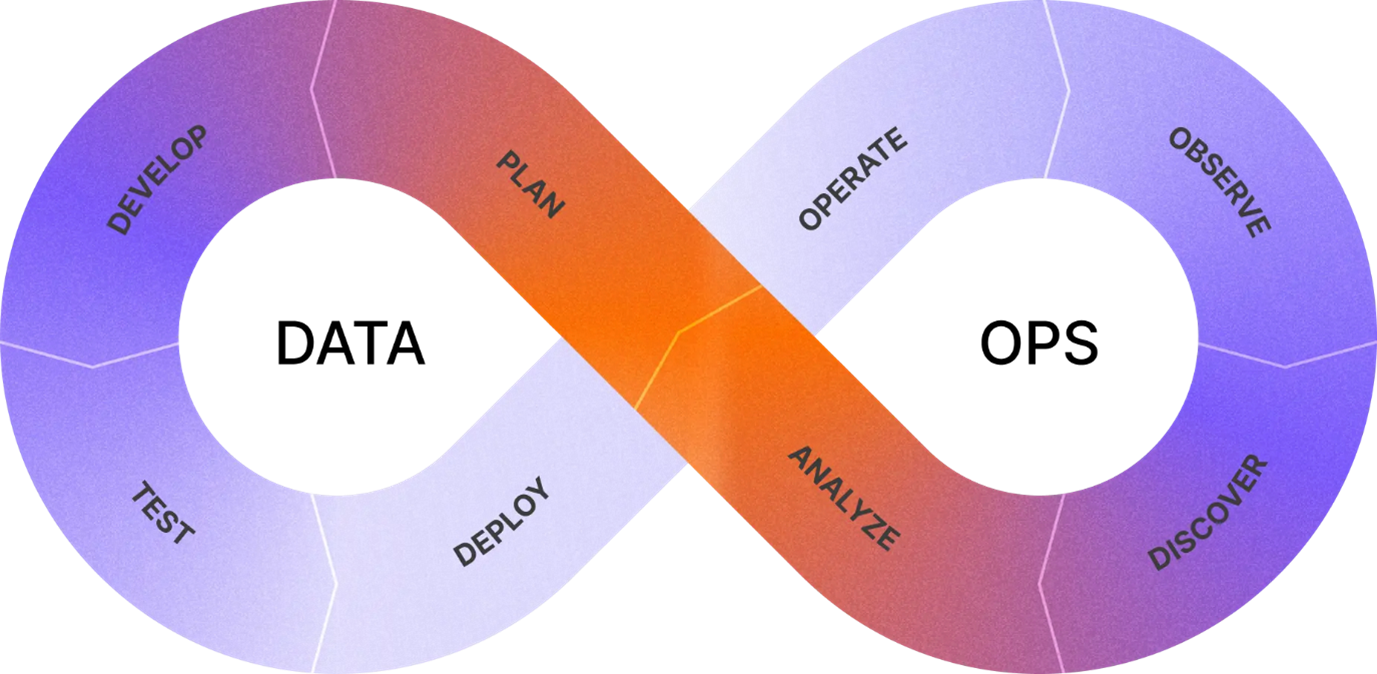
L’ADLC est un cycle itératif en 8 phases :
- Plan : définit le business case, anticiper les impacts, préparer un plan de test et de maintenance,
- Develop : la phase de développement est celle qui attire le plus d’attention mais elle peut être fluidifiée en se penchant sur la qualité du plan,
- Test : valider la robustesse et la qualité des assets,
- Deploy : mise en production avec CI/CD,
- Operate : assure la stabilité et la maintenance,
- Observe : monitore la performance et détecte les anomalies,
- Discover : explore et documente les assets existants,
- Analyze : produit des insights pour la prise de décision.
En démocratisant ce principe, dbt s’assure d’une culture de l’analytique partagée et mature qui fournit les outils pour construire des flux répondant à ce modèle.
Pour résumer, dbt permet de construire des pipelines de transformation de données comme on le ferait avec Python, par exemple. Mais si c’est déjà possible en utilisant les langages de programmation courants, alors pourquoi changer de technologie ? Si vous vous posez également cette question, la suite devrait donc vous intéresser !
Les avantages concurrentiels de la solution DBT
D’après mon expérience, voici la synthèse des principaux avantages de l’outil :
| Avantage | Explication pour Néophyte |
| SQL Natif (Simplicité) | Les analystes qui connaissent le SQL peuvent créer et maintenir des modèles sans apprendre un langage de programmation complexe (comme Python ou Scala). |
| Gouvernance et Qualité | Force l’ajout de tests (unicité, non-nullité) et de documentation directement dans le code, améliorant la fiabilité des données. |
| Versioning (Git) | Permet de suivre les changements, de revenir en arrière et de collaborer comme de vrais développeurs (intégration avec Git). |
| Linéage (Data Lineage) | Construit automatiquement un graphe de dépendances (un arbre) des transformations. On sait exactement quelle table dépend de quelle autre. Crucial pour le débogage. |
| Mise à jour intelligente (Matérialisation) | Gère la manière dont les tables sont construites (vues, tables complètes ou mises à jour incrémentales), optimisant les coûts et la performance. |
Nous arrivons enfin à la partie qui nous intéresse vraiment.
Le principal avantage d’utiliser dbt est de pouvoir manier principalement le SQL. Ce langage a l’avantage d’être populaire et connu aussi bien des Data Analysts que de la plupart des développeurs. Pour aller plus loin, on trouve même de plus en plus de testeurs ou de profils fonctionnels capables de l’utiliser.
Cet avantage permet de déplacer la tâche de transformation des données vers des profils plus métier sans la nécessité de les former à un langage de programmation tel que Python ou Spark. En déplaçant cette responsabilité, on fluidifie les échanges entre technique et fonctionnel tout en permettant d’augmenter la charge ET la qualité (d’une pierre deux coups) !
Dbt intègre nativement les concepts de tests et de documentation directement dans le code source. Ici aussi, les tests sont de simples requêtes SQL sous forme d’assertion. Cela veut principalement dire que tous les tests pouvant être traduits par une requête SQL sont logiquement implémentables dans dbt. Cette technique permet d’améliorer l’intégrité des modèles SQL. Seule subtilité : les tests construits de cette manière ne retournent aucune ligne quand ils sont valides.
Petite explication : Si je veux vérifier qu’une colonne ne contient que des emails, alors je dois écrire une requête capable d’identifier une chaîne de caractères qui n’est pas un email. De même, si je veux qu’une de mes colonnes soit unique, alors ma requête sélectionne les doublons possibles dans cette colonne.
La documentation est générée par des fichiers YAML et déployée au format web. Les fichiers YAML sont faciles à comprendre : il suffit d’ajouter une section description au fichier YAML associé au modèle et à chaque champ afin de transmettre l’utilité fonctionnelle de ces derniers. Un autre moyen plus générique, dans le cas d’utilisation multiple d’un champ, est d’associer un fichier .md, contenant les informations de ce champ comme sa description, au fichier YAML. Ainsi, la documentation ne s’écrit qu’une fois et est automatiquement déployée avec les modèles.
De plus, dbt s’intègre aisément avec Git pour utiliser le versioning, suivre les évolutions et revenir en arrière si besoin. L’outil peut construire automatiquement un graphe de Data Lineage qui permet d’illustrer les dépendances et les transformations. Cela permet de savoir exactement quelle table dépend de quelle autre table. Un avantage crucial pour le débogage !
Comparatif des avantages face à d’autres stacks
Face à des outils comme Talend ou Informatica qui s’intègrent généralement dans une stack ETL, dbt se démarque sur :
- Son coût et sa maintenance, car il est souvent moins cher et plus lisible : ce qui favorise sa maintenabilité.
- Son intégration directe au Data Warehouse : ce qui permet d’utiliser la puissance de calcul de ce dernier.
- Sa flexibilité au travers d’une configuration graphique moins complexe et plus de contrôle par le code (SQL).
Cependant dbt est centré sur le SQL ce qui impose des limites, les transformations complexes ou l’intégration de machine learning nécessitent souvent de le coupler avec Python (Spark / Pandas)
Face à une stack Airflow / Python / SQL, DBT est :
- Un outil plus accessible et permet une courbe d’apprentissage plus douce que de coder des transformations dans Python (même si les deux sont souvent complémentaires, Airflow gérant le scheduling et dbt la transformation).
- Une structure standardisée (tests, documentation, lineage) que les scripts Python n’ont pas naturellement.
En revanche, DBT n’est pas un scheduler. Il a besoin d’outils comme Airflow ; heureusement, dbt Cloud simplifie cela énormément.
Conseil de l’expert & retour d’expérience
Par le passé, j’ai eu à modéliser des pipelines de données complets, de la source à la livraison. L’un de mes projets s’articulait autour d’une architecture de microservices GCP gérés par une combinaison de Terraform, SQL et Python. L’architecture Microservices était particulièrement bien pensée et permettait d’être modulable et scalable en fonction des besoins.
Le problème ? Il a fallu plus de développeurs Python que de Data Engineers connaissant GCP et Terraform. Les besoins métiers étaient complexes à comprendre et à retranscrire avec exactitude à partir d’échanges entre les sachants et les techs.
Rétrospectivement, si je devais donner mon avis sur ce projet : je suis heureux d’y avoir participé mais en y repensant, j’ai le souvenir que tout le monde, y compris les profils fonctionnels, maîtrisait le SQL. Et tout en étant le seul langage connu de tous, il ne représentait qu’un quart du code produit.
Aujourd’hui, j’utilise dbt pour une mission assez similaire dans un autre contexte et cela représente 60% de la stack technique. Je pense que si nous avions fourni cet outil à nos Data Analysts, ou à n’importe quelle personne de l’équipe, le déroulement du projet aurait été beaucoup plus fluide. L’écriture des requêtes métier aurait pu être directement réalisée par les profils fonctionnels : ce qui représente un atout considérable dans un projet Data. De mon point de vue, cela permet de remettre l’église au milieu du village : un projet Data doit se concentrer sur la data et donc sur le SQL (CQFD).
Conclusion : l’avenir de la stack analytique moderne
L’avènement des Cloud Data Warehouses, comme Snowflake, Google BigQuery, ou encore Amazon Redshift, a marqué la transition de l’ETL vers l’ELT, rendant l’étape de Transformation la plus critique du pipeline de données. Face à ce changement, dbt s’est imposé comme un nouveau standard pour cette transformation, révolutionnant la manière dont les Data Engineers et les Analystes travaillent.
Dbt permet d’appliquer les meilleures pratiques DataOps à l’ensemble de la stack analytique. Il standardise et formalise la création de modèles de données, ce qui est fondamental à une époque où le volume de données est vertigineux et où entre 60 et 73% des données brutes ne sont jamais utilisées.
L’avenir de la stack analytique sera axé sur l’intégration et la maturité. Dbt manque d’un scheduler mais fonctionne en synergie avec des outils comme Airflow (pour l’ordonnancement). Il est également de plus en plus couplé à des langages comme Python (Spark/Pandas) pour les transformations les plus complexes ou l’intégration du Machine Learning. La solution dbt Cloud simplifie d’ailleurs grandement le déploiement, l’orchestration et la collaboration.
Cette tendance à l’unification s’est concrétisée récemment par la fusion de Fivetran et dbt Labs. Fivetran, leader de la phase Extraction et Chargement (EL) du pipeline, est réputé pour son vaste catalogue de connecteurs entièrement gérés et automatisés. En combinant l’automatisation de l’ingestion de Fivetran avec la puissance de transformation de dbt, les entreprises peuvent désormais orchestrer l’intégralité du workflow ELT de manière unifiée et fluide. Cette convergence simplifie radicalement la complexité des pipelines de données, réduit la latence entre la collecte des données brutes et l’obtention d’informations exploitables, et permet aux équipes data de se concentrer sur l’analyse à forte valeur ajoutée.
En ligne avec cette vision d’un avenir plus performant et intégré, l’introduction du moteur dbt Fusion marque la prochaine étape. Il promet une performance exceptionnelle (jusqu’à 30 fois plus efficace) et une expérience développeur enrichie. Ce moteur nouvelle génération apporte la validation SQL en temps réel et une traçabilité avancée (suivi précis des modèles et des colonnes). Cette avancée permettra de déployer des charges de travail de transformation de manière encore plus efficace et rapide, assurant ainsi que dbt puisse opérer à une échelle et à une vitesse inédites.
En conclusion, en faisant de SQL un véritable langage de développement analytique, dbt a transformé un processus complexe et technique en une démarche agile, gouvernée et accessible. Il ne fait aucun doute que dbt peut devenir la clé de voûte de la Data Stack moderne, assurant que les montagnes de données brutes puissent être transformées en un avantage concurrentiel tangible pour les entreprises.
Sources :
- https://findstack.fr/resources/big-data-statistics#key-big-data-statistics
- https://docs.getdbt.com/docs/build/data-tests
- https://docs.getdbt.com/docs/build/documentation
- https://learn.getdbt.com/learn/course/dbt-fundamentals-vs-code
- https://www.getdbt.com/blog/announcing-the-fivetran-dbt-cloud-integration
- https://docs.getdbt.com/docs/fusion/about-fusion