
Apache Kafka, le message-broker du big data

Genèse, Concepts et Fonctionnement du message-broker du Big Data
Kafka est un système de messagerie distribué open-source dont le développement a débuté chez LinkedIn en 2009, et est maintenu depuis 2012 par la fondation Apache. Tolérant aux pannes, performant, hautement distribuable et adapté aux traitements batchs comme streams, Kafka a su mettre les arguments pour devenir un standard incontournable dans les pipelines de traitements de données actuelles.
Dans cet article, nous ne parlerons pas de comment utiliser Kafka dans votre projet. Nous allons essayer de comprendre ce qui explique la success-story de Kafka, de sa genèse à ses concepts visibles comme internes.
Kafka, les origines
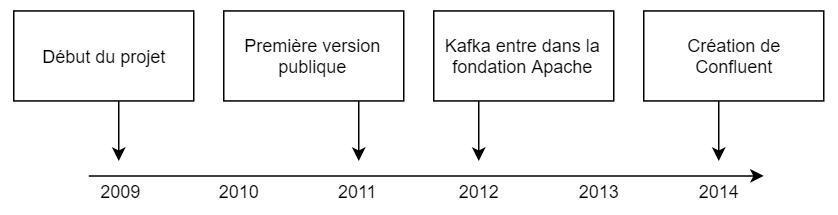
En 2009, les équipes d’ingénieurs de LinkedIn ont eu pour mission d’entièrement ré-architecturer le système. Cela a débuté par un découpage en microservices de l’architecture monolithique historique, ce qui a d’abord permis une scalabilité plus aisée. Cette refonte a ensuite mené à la création d’un ensemble de services intermédiaires afin de fournir une API permettant d’accéder aux modèles de données et aux différentes bases de données.
Afin de traquer les événements du site (pages vues, messages, etc…), ces équipes d’ingénieurs ont été amenées à développer un grand nombre de data pipelines maison pour leurs besoins, que ce soit en streaming, en queue ou en batch, ce qui leur a permis d’agréger les logs. Ces pipelines ont aussi été amenés à pouvoir scaler. Cependant, la maintenance d’un aussi grand nombre de systèmes différents rendait les pipelines difficiles à maintenir et à faire évoluer. Les équipes d’ingénieurs de LinkedIn ont donc fait le choix de créer une unique plateforme distribuée : Kafka est né.
En 2011, les sources du projet sont ouvertes, ce qui fait de la version 0.6 la première version publique du projet.
L’incubateur Apache s’intéresse au projet et le fait entrer dans la fondation en 2012.
Deux ans plus tard, en 2014, une partie de l’équipe à l’origine de Kafka quitte LinkedIn pour créer Confluent, une entreprise qui va travailler activement au développement de Kafka et d’une plateforme autour de ce dernier, la « Confluent Platform ».
Concepts
Kafka a donc initialement été créé pour répondre aux importants besoins de LinkedIn et pour s’adapter au maximum à n’importe quel besoin. Kafka utilise le concept très connu du publish / subscribe, mais en s’appuyant sur le disque dur pour fonctionner. Il exploite également de nombreuses astuces de conceptions au plus bas niveau afin de devenir le broker le plus rapide du marché.
Afin d’introduire Kafka, nous commencerons par expliquer le principe du publish / subscribe pour ensuite nous intéresser à son implémentation dans Kafka en définissant les différentes briques du système. Nous verrons enfin quelles sont les optimisations internes permettant à ce message-broker d’aller aussi vite.
Publish / Subscribe
Afin de permettre à tous de comprendre le concept de publish / subscribe (souvent appelé pub-sub) qui est central dans Kafka, nous allons commencer par une analogie postale.

Lorsque l’on regarde le graphique ci-dessus nous pouvons voir que :
- Milan Jeunesse et Disney éditent tous les deux des magazines pour enfants : « Toupie » pour Milan, « Le Journal de Mickey » pour Disney.
-
M. Twilight et Mme. Pinky se sont abonnés au Journal de Mickey et peuvent donc régulièrement aller chercher le journal dans leur boîte aux lettres.
-
M. Dupont et Mme. Pinky peuvent faire de même pour le magazine Toupie.
Néanmoins, ce graphique n’est pas figé :
- Si demain, Disney passe un accord avec Milan, Milan pourra lui aussi éditer le Journal de Mickey.
-
Quand la fille de Monsieur Dupont aura grandi, ce dernier pourra changer de magazine en se désabonnant de Toupie et en s’abonnant au Journal de Mickey.
-
Un nouvel éditeur, Play Bac Press, peut aussi très facilement proposer un nouveau journal : « Mon Quotidien » et d’autres personnes pourront s’y abonner.
Maintenant, imaginez la même chose au sein d’une architecture logicielle. Nous sommes face à une architecture modulable dans laquelle tout le monde peut accéder à l’information qui l’intéresse, et ce en temps réel, et surtout de façon extrêmement scalable. C’est ce que propose le design « Publish / Subscribe ».
Publish / Subscribe est un design de système de messages permettant de mettre en place un mécanisme de publication et d’abonnement. Les publishers (les éditeurs dans notre exemple) ont pour rôle d’envoyer des messages (numéro du magazine) dans des topics (magazine). Les consumers (abonnés) peuvent donc régulièrement aller regarder dans les topics si de nouveaux messages sont arrivés.
Les publishers n’ont donc jamais connaissance des consumers, l’inverse étant également vrai. La mise en place d’un tel système permet à deux consumers de profiter des mêmes informations, ou permet à deux publishers de remplir le même topic de manière transparente.
Comprendre le design pattern publish / subscribe est obligatoire pour pouvoir utiliser Kafka puisqu’il en est l’un des principes fondateurs. Passons maintenant à ce qui nous intéresse : Kafka.
Kafka
Dans le vocabulaire Kafka, on nomme :
- Producer : tout système qui envoie des données dans un ou plusieurs topics Kafka. (Publisher dans pub-sub)
-
Consumer : tout système qui lit des données dans un ou plusieurs topics Kafka. (Subscriber dans pub-sub)
-
Broker : tout serveur Kafka.
-
Cluster : Ensemble de broker.
Message
Ce qu’envoie un producer et ce que reçoit un consumer, c’est un message. Au plus bas niveau, les messages ont la structure suivante :
Objet MessageAndOffset
| Champ | Taille | Description |
| MessageSize | 32 bits | Taille du Message. |
| Offset | 64 bits | Index unique de chaque message. |
| Message | bytes | Voir Objet Message. |
Objet Message
| Champ | Taille | Description |
| CRC | 32 bits | Contrôle de Redondance Cyclique : permet de vérifier l’intégrité d’un message au niveau du broker et du consumer. |
| MagicByte | 8 bits | Identifiant de la version de Kafka utilisé pour la rétrocompatibilité. |
| Attributes | 8 bits | Cet octet contient les métadonnées du message (codec de compression…). |
| Timestamp | 64 bits | Timestamp du message. |
| KeySize | 32 bits | Taille de la clé. |
| Key | bytes | La clé est optionnelle (peut être nulle) et est utilisée pour l’assignation à une partition. |
| ValueSize | 32 bits | Taille du contenu. |
| Value | bytes | Contenu du message dans un byte-array « opaque ». |
Nous pouvons remarquer différentes choses :
- Kafka ne définit pas la façon dont sont formatés vos messages, il ne sait pas ce qu’il fait transiter. Il va donc être de votre ressort de choisir le format de vos données (cela peut-être du JSON, du XML, du Turtle, du Protobuf ou même du binaire dont vous seul avez le secret).
-
Chaque message dispose d’un CRC permettant de vérifier son intégrité. Pas besoin de vous préoccuper de cette partie donc, Kafka le fait pour vous.
-
Les messages peuvent être compressés de bout en bout. C’est à vous de le configurer au niveau du producer et les données seront décompressées uniquement au niveau du consumer.
-
Chaque message est identifié par un Offset. Voir partie « Log ».
Log
Chaque message envoyé par un producer dans un topic et reçu par un consumer sera encapsulé au sein d’un log. Ici, log ne veut pas dire journal d’événements comme on en a l’habitude en informatique, il s’agit plus d’un modèle de données ressemblant à une file d’attente (ou queue).
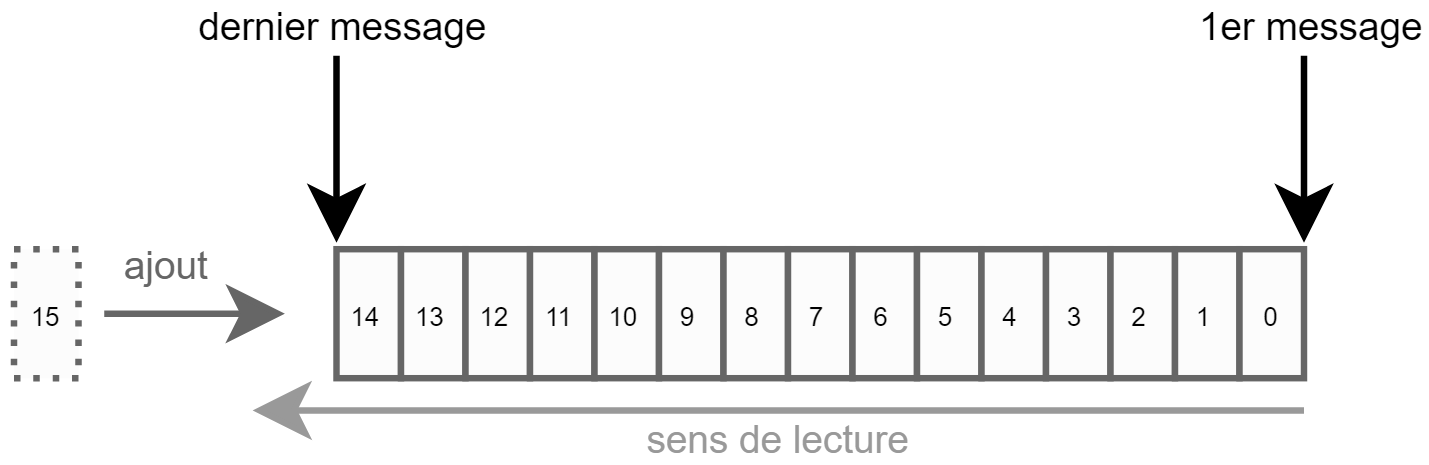
À la manière d’une file d’attente, le log est un tableau de messages ordonnés par rapport à leur ordre de réception.
Comme nous l’avons vu précédemment, chaque message a un identifiant unique nommé « Offset ». Lorsqu’un consumer récupère des messages, il existe deux possibilités :
- Si le consumer donne un offset, on récupère tous les messages qui sont arrivés depuis dans le log.
-
Si le consumer ne donne pas d’offset, il récupère l’intégralité des messages.
Contrairement aux autres brokers de messages, Kafka ne maintient pas une liste des consumers et de leur avancement. Chaque consumer est donc responsable de son avancement dans la lecture des messages ; c’est à lui de faire attention à ne pas lire un message en double par exemple.
Topics
A plus haut niveau, vous vous en doutez, nous ne manipulons pas des logs directement mais des topics. Un topic permet de représenter une catégorie, un type de données. Si l’on reprend notre exemple de l’introduction, « Le journal de Mickey » et “Toupie” sont des topics.

Les producers envoient donc des messages dans des topics, les consumers vont chercher des messages dans ces mêmes topics.
Partitions
Un topic peut être divisé en partitions. Par exemple, lorsque l’on crée le topic « Le journal de Mickey », nous pouvons choisir de le découper en deux partitions. Le serveur va donc créer deux logs, un par partition. Lorsqu’un producer envoie un nouveau message dans un topic, il sera assigné à une partition et ajouté uniquement à cette partition.
Commençons avec deux consumers et un topic séparé en deux partitions sur un seul broker Kafka. En fonction de la clé du message (qui est optionnelle), le producer poussera le message dans une partition ou dans l’autre. Chaque consumer n’ira lire que dans la partition qui lui aura été assignée. Les messages avec la même clé iront donc tous dans la même partition / le même consumer.
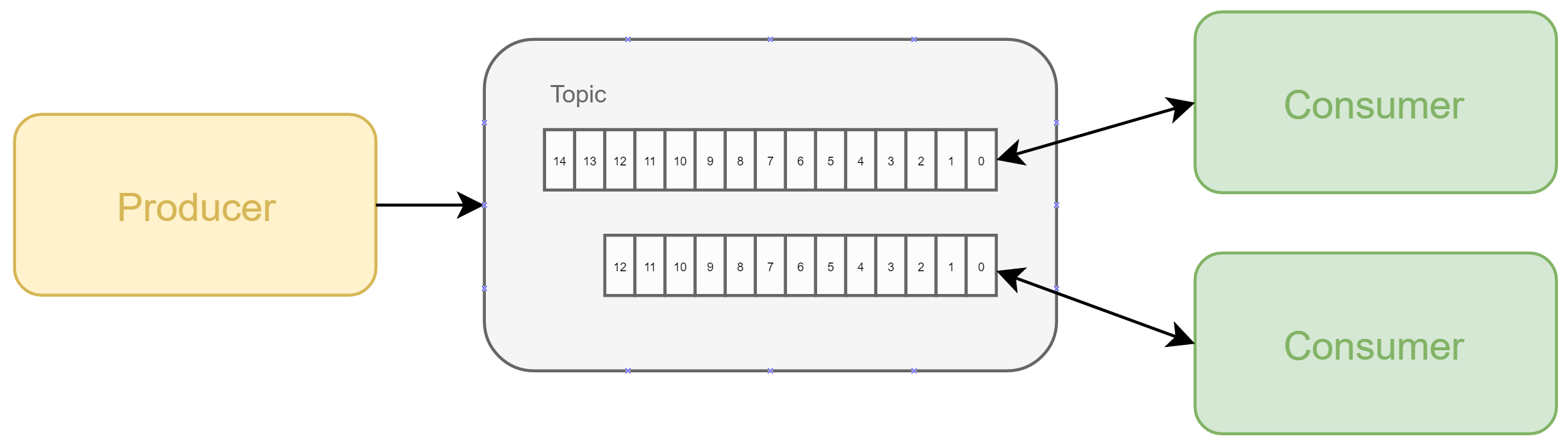
Maintenant, essayons de complexifier un peu ce scénario. Créons un cluster Kafka avec deux brokers hébergés sur deux machines distinctes. Lorsque l’on va partitionner le topic, nous allons configurer deux partitions et deux réplicas, chaque broker ayant sa partition ainsi que le réplica de la partition de l’autre. Chaque broker est donc « maitre » d’une partition.
Lorsqu’un producer va envoyer un message, il va l’envoyer au maitre de la partition. Le maitre va enregistrer le message dans son log en local. Le second broker ira, de manière passive, répliquer le contenu du maitre dans son propre log. Si jamais le maitre de la première partition tombe, le deuxième prendra le relais et deviendra alors le nouveau maitre. Le mécanisme est le même pour les consumers.
Le partitionnement d’un topic est très bénéfique car il permet d’effectuer du load-balancing du côté des brokers et des clients avec assez peu de travail. Kafka est fortement distribué et tolérant à la panne grâce à ce mécanisme.
Dans les tripes de Kafka
Depuis plusieurs années, Kafka est littéralement devenu un leader incontournable dans son domaine, venant petit à petit détrôner ses principaux concurrents comme RabbitMQ ou encore ActiveMQ. Cela s’explique notamment par sa simplicité d’utilisation et de déploiement, mais surtout par ses performances.
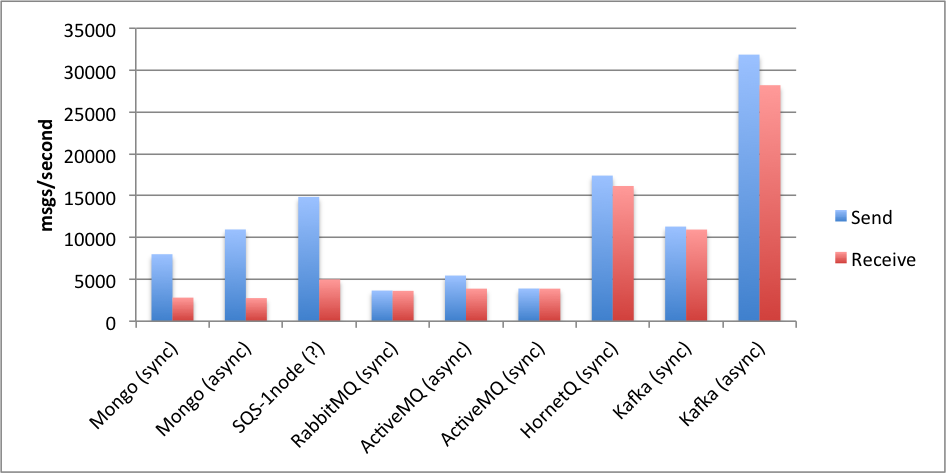
(source : https://softwaremill.com/mqperf/)
Comment Kafka fait-il pour avoir d’aussi bonnes performances alors qu’il écrit sur le disque ?
On vous a rabâché pendant des années que « tout est plus rapide que la lecture et l’écriture sur disque dur » ? Regardez plutôt.

(source : https://queue.acm.org/detail.cfm?id=1563874 (Article que je vous invite chaleureusement à lire))
Il se trouve que le célèbre adage que l’on vous a répété un certain nombre de fois pendant vos études en informatique n’est pas totalement vrai. La façon de stocker les données sur un disque dur influence grandement les performances. En effet, si l’on écrit de manière naïve sur un disque dur, les données seront distribuées sur l’ensemble du disque en morceaux indexés dans la table d’allocation. Nous n’allons pas entrer dans les détails, mais on comprend très rapidement que le disque dur qui fonctionne sur un système mécanique devant bouger physiquement la tête de lecture pour aller chercher chacun des morceaux mettra bien plus de temps si les morceaux sont éparpillés que s’ils sont les uns à la suite des autres. Les données enregistrées de manière séquentielle, les unes à la suite des autres, sont donc plus rapidement accessibles sur un support mécanique, mais pas seulement. Le fait d’aller chercher des morceaux et de les rassembler a un coût, et même s’il paraît négligeable à petite échelle, chaque coût négligeable à petite échelle devient un enfer à grande échelle.
« Séquentiel : Qui appartient, se rapporte à une séquence, à une suite ordonnée d’opérations. » – Larousse
Vous ne trouvez pas que la définition du mot séquentiel ressemble à quelque chose que l’on a déjà vu dans cet article ? Effectivement, le log est un modèle de données purement séquentiel et ce n’est pas un hasard.
Le mécanisme zero copy
Dans beaucoup d’applications, nous récupérons des données d’un endroit A pour les enregistrer à un endroit B sans aucune transformation. C’est le cas lorsqu’un consumer récupère les messages d’un topic. En réalité, cela revient à aller lire les messages sur le disque et à les renvoyer directement dans un socket. La manière traditionnelle pour coder cela est :
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
Sauf qu’à ce moment très précis, nous avons ajouté un intermédiaire invisible : l’application. Lorsque l’on enregistre la donnée dans un buffer afin de la pousser de l’autre côté, on perd du temps et de la ram.
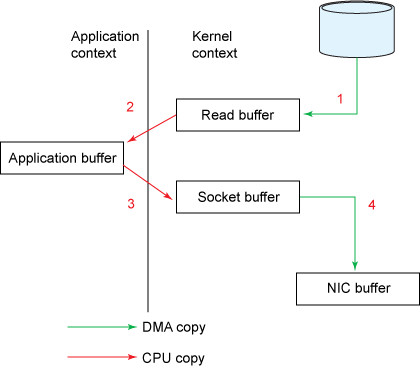
(source : https://www.ibm.com/developerworks/library/j-zerocopy/)
C’est là que le mécanisme zero copy entre en jeu. L’idée derrière zero copy est simple : au lieu de copier la donnée dans le buffer de l’application avant de la copier dans le socket, nous allons la copier directement depuis la source dans le socket. Java supporte nativement ce mécanisme avec la fonction transferTo() du package java.nio.channels.FileChannel.
transferTo(position, count, writableChannel);
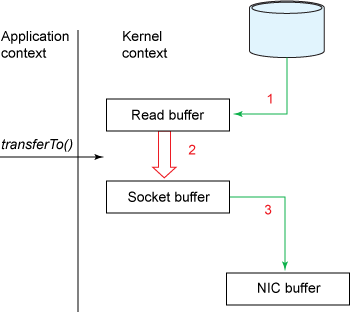
(source : https://www.ibm.com/developerworks/library/j-zerocopy/)
| Attention néanmoins si vous souhaitez utiliser les APIs issues du package nio de Java dans vos projets. Effectivement, ce package fournit des fonctionnalités permettant de travailler à bas niveau et cela n’est pas sans danger. |
La différence entre transferTo() et la méthode traditionnelle est assez impressionnante car on remarque un gain de 60% en performance !
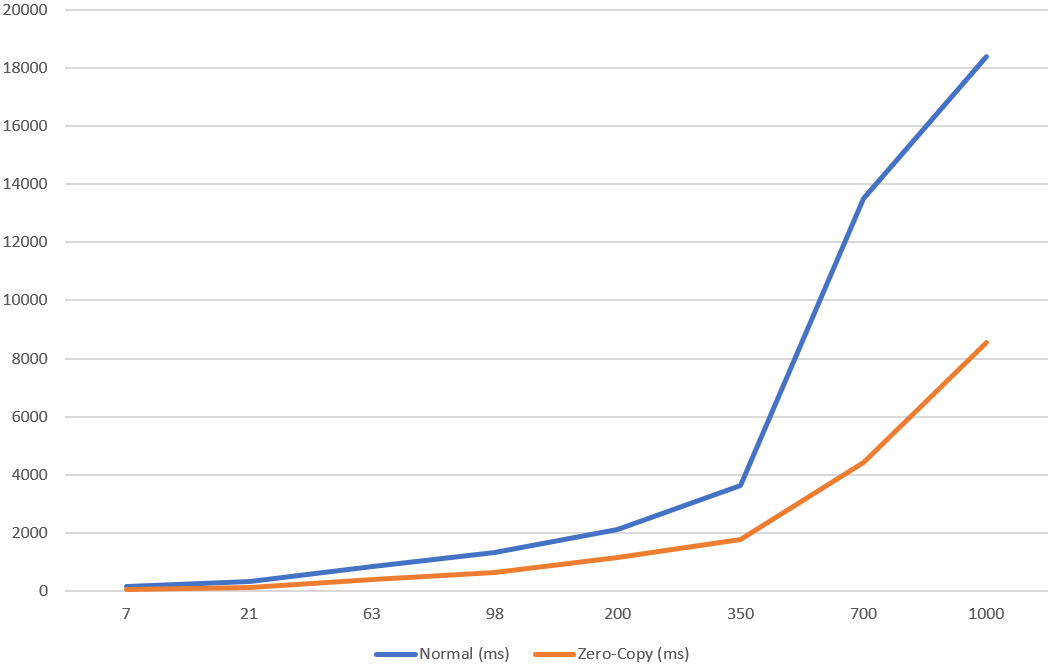
ZooKeeper
Réponse de la CTO d’Apache Kafka à la question « Peut-on avoir un cluster Kafka sans Zookeeper ? »
Apache Kafka est dépendant d’Apache ZooKeeper. Sans entrer dans les détails, car expliquer le fonctionnement de ZooKeeper mériterait un article à part entière, il s’agit en quelque sorte d’une boîte à outils pour systèmes distribués. Il est lui-même conçu pour être distribué et répondre à des problématiques de haute disponibilité.
Pour en savoir plus sur ZooKeeper, je vous invite à regarder cette vidéo des éditions O’Reilly (en anglais) : https://www.youtube.com/watch?v=40aoPoSP2H8
Conclusion
Cet article vous aura, nous l’espérons, permis de découvrir Kafka, ses concepts, ses principaux choix architecturaux qui en font aujourd’hui un message broker reconnu sur le marché. Pour finir et pour vous permettre de vous faire une idée, nous vous invitons à vous renseigner sur les entreprises utilisant aujourd’hui Kafka en production depuis plusieurs années. De la gestion du flux des logs aux architectures événementielles, il existe beaucoup d’usages, tous très intéressants à regarder.
- Architecture événementielle chez Meetic (https://fr.slideshare.net/VincentLepot/archictecture-evenementiellemeetic?qid=acd402b4-bf21-4162-927c-aaece11ff590&v=&b=&from_search=6)
-
Gestion des logs chez Netflix (https://techblog.netflix.com/2016/02/evolution-of-netflix-data-pipeline.html)
-
Anti-DDoS chez OVH (https://www.slideshare.net/LostInBrittany/steven-le-roux-kafka-et-storm-au-service-de-la-lutte-antiddos-ovh-soire-big-data-du-finistjug)
-
Pipeline temps réel centrale chez Uber (https://fr.slideshare.net/ConfluentInc/kafka-uber-the-worlds-realtime-transit-infrastructure-aaron-schildkrout)
-
Gestion des logs chez Dropbox (https://fr.slideshare.net/ConfluentInc/deploying-kafka-at-dropbox-mark-smith-sean-fellows)